CUDA Cores vs. Tensor Cores
이 글에서는 Nvidia의 CUDA Core와 Tensor Core의 차이점에 대해 알아보겠습니다. 마지막에는 Nvidia가 Turing 아키텍쳐와 함께 발표한 Turing Tensor Core에 대해서도 알아봅니다.
CUDA Cores#
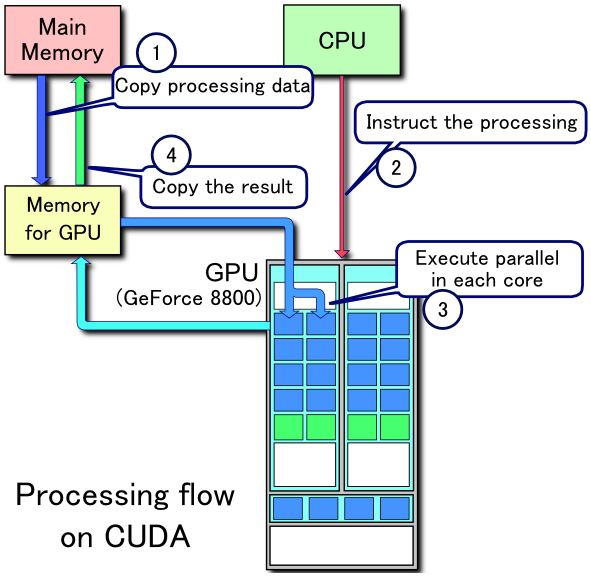
먼저 CUDA Core란 무엇인지에 대해 짚고 넘어가 봅시다. 한 줄로 요약하면, Nvidia GPU에서 CUDA Core가 하는 일은 CPU에서 CPU core가 하는 일과 같습니다. 차이점은 CUDA Core는 더 많은 수가 동시에 병렬로 연산하도록 설계되었다는 점입니다. CUDA Core는 CPU core보다 더 단순한 구조, 더 적은 캐시, 더 작은 instruction set, 더 낮은 clock rate를 갖습니다. 대신 일반적인 CPU가 1개에서 8개 정도의 core를 갖는 것에 비해 GPU는 보통 수 백개에서 수 천개의 core를 갖습니다. 따라서 GPU는 단순한 연산의 병렬 처리가 많은 그래픽 및 머신 러닝 작업에 적합합니다.
CUDA Cores vs. Stream Processors#
AMD는 자사의 GPU core를 Stream Processor라고 부릅니다. CUDA Core와 Stream Processor의 역할은 같습니다. 그러나 두 회사의 GPU 아키텍쳐는 다르기 때문에 CUDA Cores의 수와 Stream Processor의 수를 직접 비교할 수는 없습니다. 즉, 500개의 CUDA Cores가 500개의 Stream Processor와 같은 성능을 갖지는 않습니다. GPU 간 정확한 성능 비교 위해서는 benchmark test를 사용합니다.
Number of CUDA Cores and computing power#
같은 세대의 GPU 내에서 CUDA Core의 수가 많다는 것은 더 많은 컴퓨팅 파워를 의미합니다.
하지만 아키텍쳐가 다른 GPU 사이에서 CUDA Core의 수를 일대일로 비교하는 것은 어렵습니다. 예컨대, Kepler 아키텍쳐에서 Maxwell 아키텍쳐로 바뀔 때 CUDA Core의 연산 능력은 약 40% 증가하였습니다. 이처럼 아키텍쳐의 차이는 CUDA Core의 수가 같더라도 효율성의 차이를 가져올 수 있습니다.
Tensor Cores#
Tensor Core를 한마디로 정리하면, 4x4 행렬 연산을 수행하는 GPU core입니다. CUDA Core가 1 GPU clock에 하나의 fp32 부동소수점 연산을 수행하는 데 비해, Tensor Core는 1 GPU clock에 4x4짜리 fp16 행렬을 두 개를 곱하고 그 결과를 4x4 fp32 행렬에 더하는 matrix multiply-accumulate 연산을 수행합니다. multiply-accumulate 연산이란 A와 B를 곱하고 C를 더하는 과정을 하나의 연산에서 한번에 수행하는 것입니다. Tensor Core의 matrix multiply-accumulate 연산을 그림으로 나타내면 다음과 같습니다.
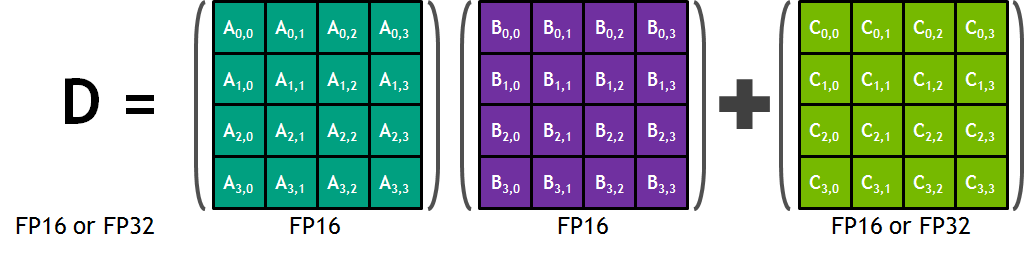
이 과정은 fp16 행렬을 입력으로 받고 fp32 행렬로 출력을 반환하기 때문에 mixed precision이라고 불립니다. Volta 이상의 아키텍쳐에 기반한 GPU에서만 딥러닝 학습 시 mixed precision을 쓸 수 있는 것은 이 때문입니다. (Volta 이전의 아키텍쳐에서는 mixed precision을 시뮬레이션할 수는 있지만 실제 속도는 빨라지지 않습니다.)
이처럼 부동소수점 연산에 사용되는 multiply-accumulate 연산은 (rounding이 한번일 때) **FMA (fused multiply-add)**라고 불리기도 합니다. 각 Tensor core는 한 번의 GPU clock에 64개의 부동소수점 FMA mixed precision 연산을 합니다. 출력 행렬의 한 원소를 계산하는 데 4개의 FMA 연산이 필요하고 총 4x4개의 원소가 있기 때문입니다. 각각의 FMA 연산을 도식화하면 아래 그림과 같습니다.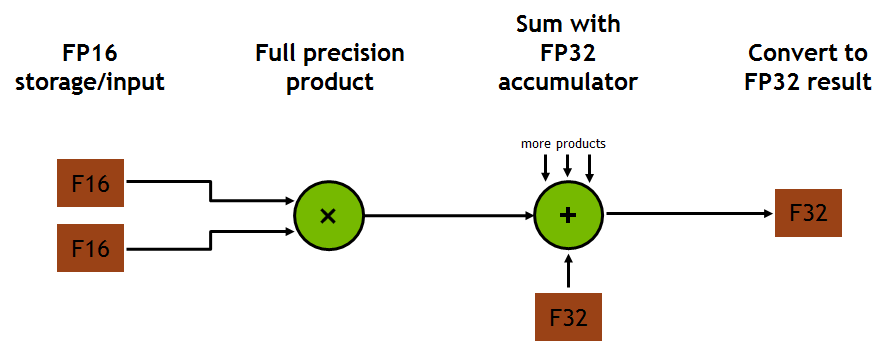
How fast are Tensor Cores#
CUDA 라이브러리인 cuBLAS와 cuDNN는 Tensor Core를 지원합니다. cuBLAS는 행렬과 행렬을 곱하는 GEMM 연산에, cuDNN은 convolution 연산에 Tensor Core를 사용합니다. Tensor Core는 cuBLAS에서 4~9배, cuDNN은 4~5배의 성능 향상을 이끌었습니다.
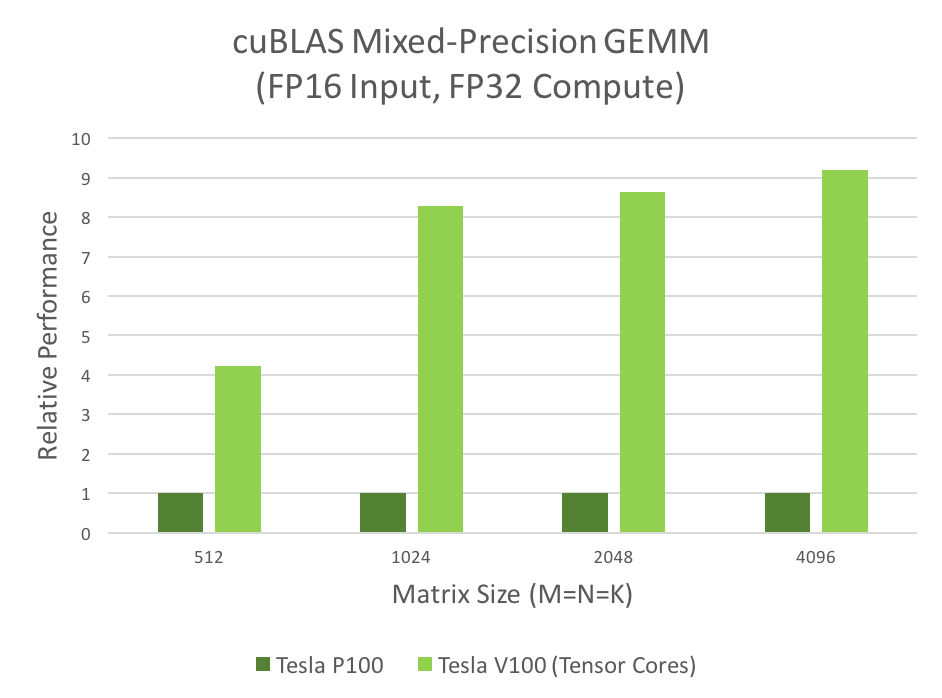
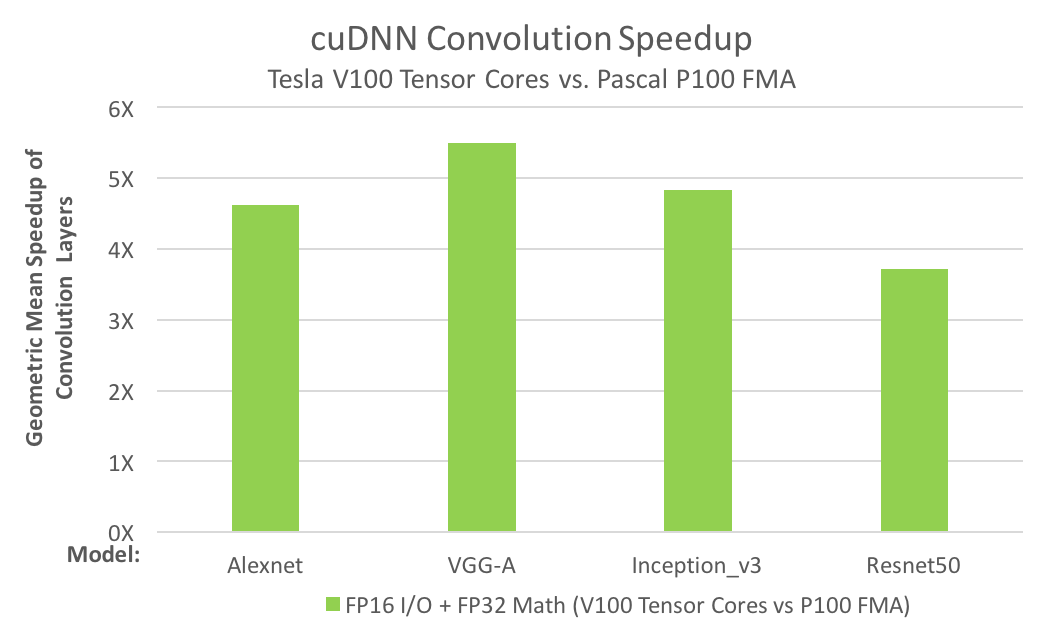
Benefits & drawbacks of Tensor Cores#
일반적으로 CUDA Core는 Tensor Core에 비해 느리지만 fp32 연산이기 때문에 더 높은 수준의 계산 정확도를 얻을 수 있습니다. 이에 비해 Tensor Core는 연산 속도가 매우 빠르지만 fp16 연산이기 때문에 어느정도 계산 정확도를 희생해야 합니다.
GPU examples#
Nvidia는 2017년에 처음 Volta microarchitecture로 만들어진 Titan V를 출시하며 Tensor Core를 상용화했습니다. Titan V와 V100은 둘 다 5120개의 CUDA Core와 640개의 Tensor Core를 갖고 있습니다.

Titan V 또는 V100의 spec을 살펴보면 딥러닝용 연산 속도가 125 teraFLOPS라고 적혀 있습니다. 이 수치가 어떻게 나오는지 직접 계산해봅시다. 하나의 Tensor core는 한 cycle에 64개의 FMA를 수행하며 이는 곱셈과 덧셈을 따로 계산하면 128개의 부동소수점 연산을 수행하는 것입니다. Titan V에는 640개의 Tensor Core가 있으므로 cycle마다 128 * 640 = 81920 번의 floating point 연산을 할 수 있습니다. V100의 GPU boost clock speed는 1.53GHz이므로 81920 FLOPS * 1.53 billion = 125.33 TeraFLOPS가 나오게 됩니다.
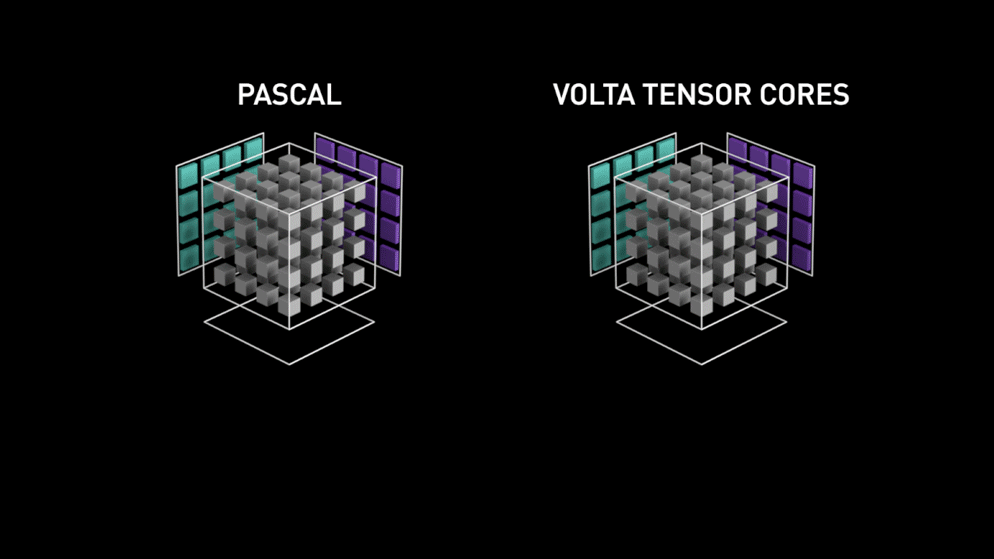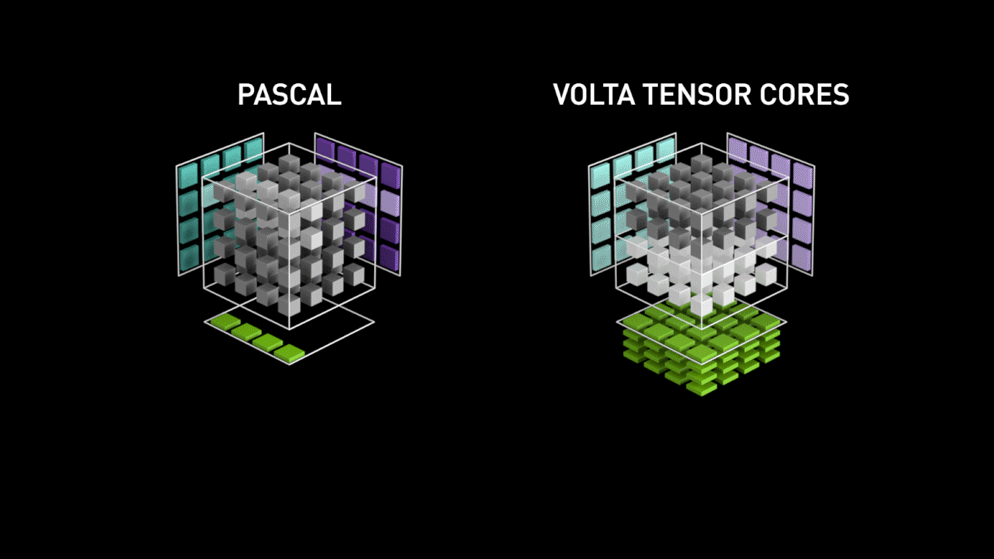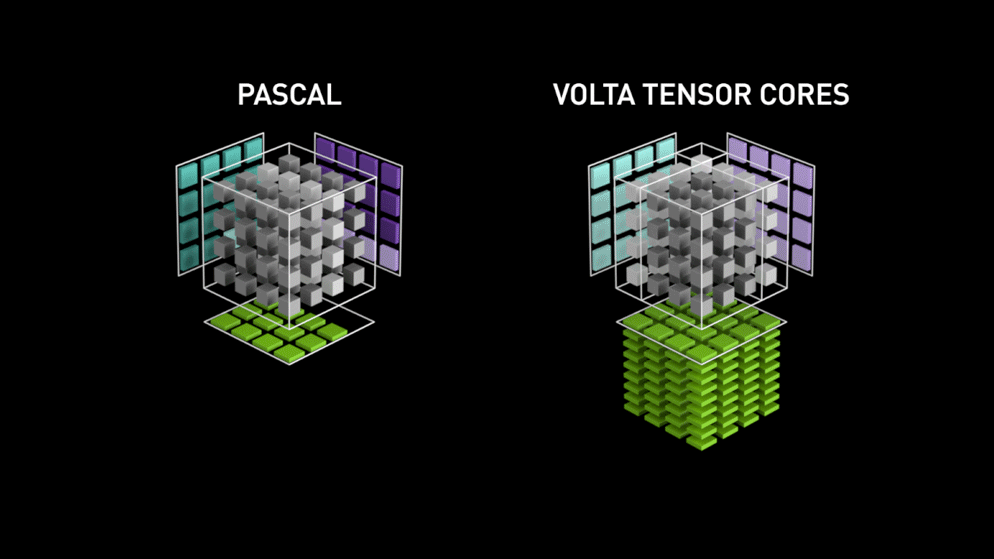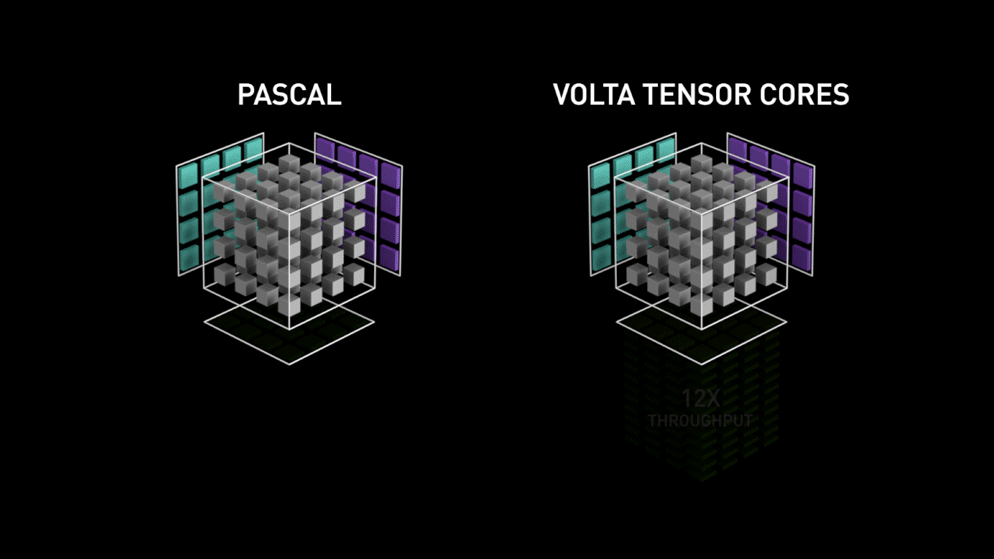
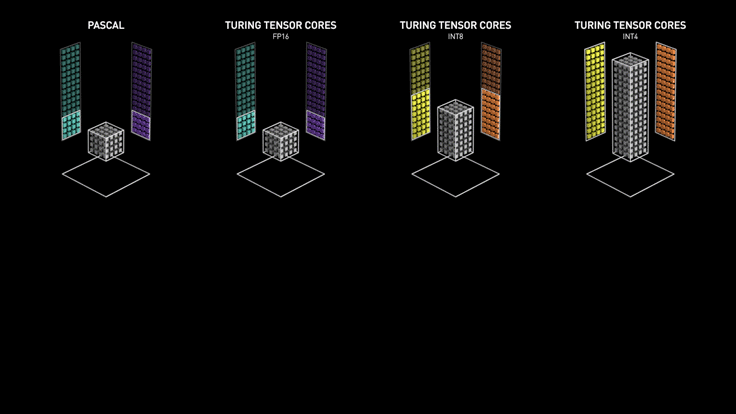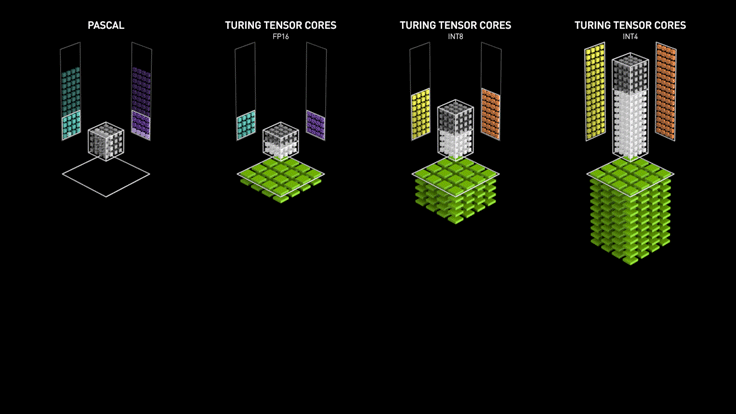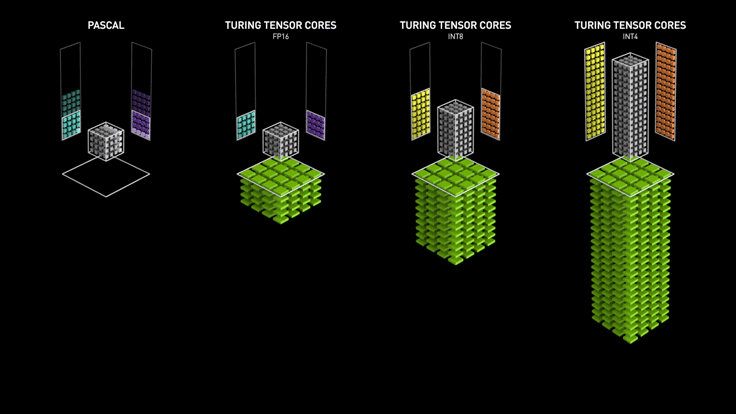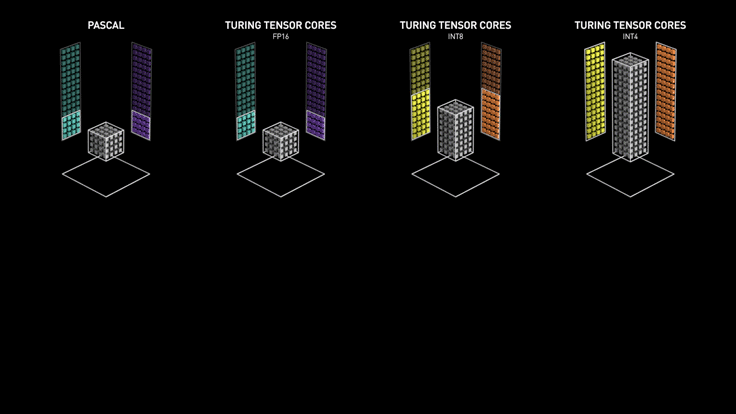
Turing Tensor Cores#
Nvidia가 Turing 아키텍쳐에 도입한 Turing Tensor Core는 Tensor Core에 딥러닝 모델의 인퍼런스를 위해 INT8과 INT4 연산을 추가했습니다. 연산에 필요한 비트 수를 낮추어 연산 속도를 빠르게 하는 quantization 기법이 적용된 모델이라면 이를 활용해서 인퍼런스 속도를 높일 수 있습니다. 아래 애니메이션에서 살펴볼 수 있듯이 비트 수가 줄어들 수록 연산 처리량은 더욱 많아집니다.
References#
- https://www.gamingscan.com/what-are-nvidia-cuda-cores/
- https://www.gamersnexus.net/dictionary/2-cuda-cores
- https://stackoverflow.com/questions/20976556/what-is-the-difference-between-cuda-core-and-cpu-core
- https://nerdtechy.com/cuda-cores-vs-stream-processors
- https://www.makeuseof.com/tag/what-are-cuda-cores-pc-gaming/
- https://towardsdatascience.com/what-on-earth-is-a-tensorcore-bad6208a3c62
- https://stackoverflow.com/questions/47335027/what-is-the-difference-between-cuda-vs-tensor-cores
- https://www.quora.com/What-is-the-difference-between-CUDA-cores-and-Tensor-cores
- http://hwengineer.blogspot.com/2018/03/v100-tensor-core.html
- https://developer.nvidia.com/blog/programming-tensor-cores-cuda-9/
- https://developer.nvidia.com/blog/nvidia-turing-architecture-in-depth