강화학습 알고리즘 분류
이 글에서는 강화학습의 여러 알고리즘들을 카테고리로 묶는 분류 체계에 대해서 알아보겠습니다. 분류 체계를 이해하면 새로운 알고리즘이 등장하더라도 기존 알고리즘과 어떤 관계에 있는지 쉽게 파악할 수 있습니다.
이 글은 David Silver의 Introduction to reinforcement learning과 OpenAI의 Spinning Up을 참고했습니다.
Major Components of an RL Agent#
강화학습의 분류 체계를 알아보기 전에 먼저 분류의 기준이 되는 강화학습 agent(행위자)의 구성 요소에 대해 알아보아야 합니다. 강화학습의 agent는 크게 다음 세가지의 요소를 갖습니다.
Policy#
Agent의 행동 패턴입니다. 주어진 state에서 어떤 action을 취할지 말해줍니다. 즉, state를 action에 연결 짓는 함수입니다. Policy는 크게 deterministic(결정적) policy와 stochastic(확률적) policy로 나뉩니다. Deterministic policy는 주어진 state에 대해 하나의 action을 주고, stochastic policy는 주어진 state에 대해 action들의 확률 분포를 줍니다.
- Deterministic Policy: $a = \pi(s)$
- Stochastic Policy: $\pi(a|s) = P[A_t = a | S_t = s]$
Value function#
State과 action이 나중에 어느 정도의 reward를 돌려줄지에 대한 예측 함수입니다. 즉, 해당 state과 action을 취했을 때 이후에 받을 모든 reward 들의 가중합입니다. 이때, 뒤에 받을 reward 보다 먼저 받을 reward에 대한 선호를 나타내기 위해 discounting factor $\lambda$를 사용합니다.
$$v_{\pi}(s) = E_{\pi}[R_{t+1} + \lambda R_{t+2} + \lambda^2 R_{t+3} + … | S_t = s]$$
Model#
environment(환경)의 다음 state와 reward가 어떨지에 대한 agent의 예상입니다. State model과 Reward model로 나눌 수 있습니다.
$$\mathcal{P}^a_{ss'} = P[S_{t+1} = s' | S_t = s, A_t = a ]$$
$$\mathcal{R}^a_s = P[R_{t+1} | S_t = s, A_t = a ]$$
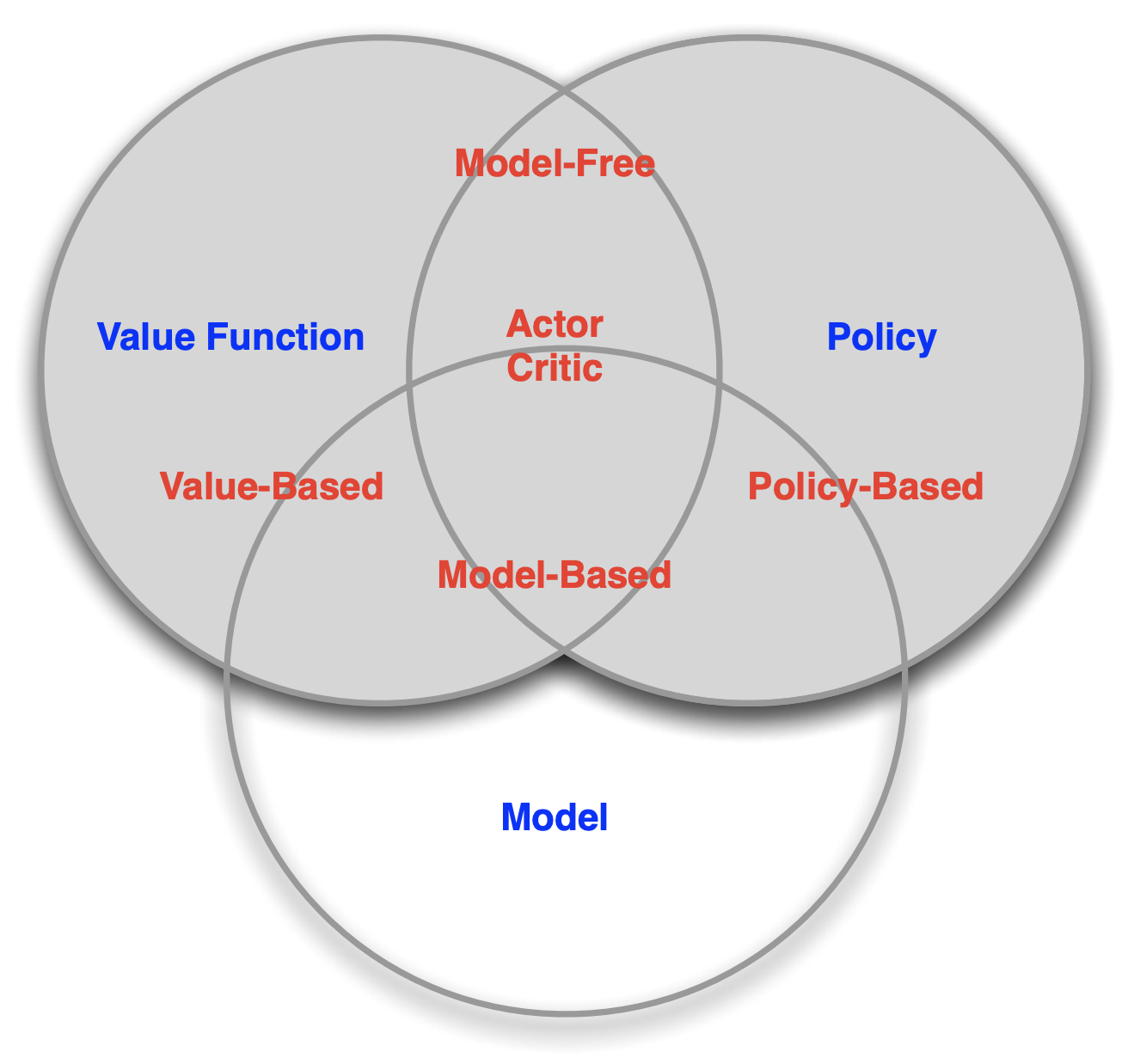
Model-Free vs Model-Based#
강화학습 알고리즘을 구분은 첫번째 구분은 environment에 대한 model의 존재 여부입니다. Model을 갖는 것은 장점과 단점이 있습니다.
Model을 갖는 것의 장점은 Planning(계획)을 가능하게 한다는 것입니다. 즉, 자신의 action에 따라서 environment가 어떻게 바뀔지 안다면 실제로 행동하기 전에 미리 변화를 예상해보고 최적의 행동을 계획하여 실행할 수 있습니다. 이와 같은 계획이 가능하다면 agent는 훨씬 효율적으로 행동할 수 있을 것입니다.
Model을 갖는 것의 단점은 environment의 정확한 model은 보통 알아내기가 어렵거나 불가능하다는 점입니다. 혹시라도 Model이 environment를 제대로 반영하지 않는다면 이 오류는 그대로 agent의 오류로 이어지게 됩니다. 정확한 model을 만드는 것은 좋은 agent를 만드는 것만큼 또는 더 어려울 수 있습니다.
Model을 사용하는 agent를 model-based라고 부르고 그렇지 않은 agent를 model-free라고 부릅니다.
Model-based agent는 다시 모델이 주어져 있는지 아니면 학습 대상인지에 따라 구분할 수 있습니다.
Value-Based vs. Policy-Based#
강화학습 알고리즘의 두번째 구분은 value function과 policy의 사용 여부입니다.
만약 value function이 완벽하다면 최적의 policy는 자연스럽게 얻을 수 있습니다. 각 state에서 가장 높은 value를 주는 action만을 선택하면 될 테니까요. 이를 implicit (암묵적인) policy라고 합니다. Value function 만을 학습하고 policy는 암묵적으로만 갖고 있는 알고리즘들이 있습니다. 이를 value-based agent라고 부릅니다. DQN 등이 여기에 해당합니다.
반대로 Policy가 완벽하다면 value function은 굳이 필요하지 않습니다. 결국 value function은 policy를 만들기 위해 사용되는 중간 계산일 뿐이니까요. 이처럼 value function이 없이 policy만을 학습하는 agent를 policy-based라고 부릅니다. Policy Gradient 등이 여기에 해당합니다.
Value-based agent는 데이터를 더 효율적으로 활용할 수 있다는 장점이 있습니다. 이에 비해 policy-based agent는 원하는 것에 직접적으로 최적화를 하기 때문에 더욱 안정적으로 학습된다는 장점이 있습니다.
두 극단적인 케이스만 있는 것은 아닙니다. Value function과 Policy를 모두 갖고 있는 agent도 있습니다. 이를 Actor-Critic agent라고 부릅니다.
Examples#
각 카테고리의 알고리즘 예시는 아래 그림에서 볼 수 있습니다. 그림에서 Policy Optimization는 policy-based를 뜻하고 Q-Learning은 value-based를 뜻합니다.
