머신 러닝 소개 (Introduction to Machine Learning)
이 글은 머신 러닝에 관심은 있지만 머신 러닝이 무엇인지는 아직 잘 모르는 사람들을 위한 글입니다. 이 글에서는 머신 러닝의 개념과 일반적인 머신 러닝 프로젝트의 진행 과정(workflow)에 대해 알아봅니다.
Introduction#
머신 러닝은 이제 일상에서 뗄레야 뗄 수 없는 존재가 되었다. 한가지 예로, 네이버의 검색 페이지에는 머신 러닝 기술이 들어가지 않은 곳을 찾아보기 힘들 정도다. 자동 완성, 음성 인식, 연관검색어, 이미지 검색, 문장 요약 등의 영역에서 수많은 머신 러닝 기술들이 쓰이고 있다.
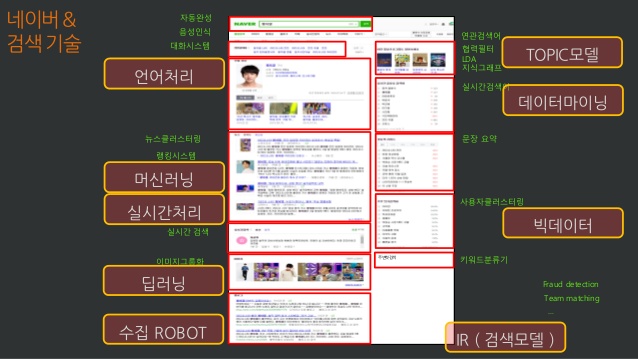
그러나 머신 러닝이란 말이 사람들 사이에서 점점 더 널리 쓰이면서, 머신 러닝이 정확히 무엇인지 알지 못하고 엉뚱한 데에 머신 러닝이란 말을 남용하는 경우가 늘어나고 있다. 머신 러닝의 개념을 명확하게 알고 사용하기 위해 머신 러닝이 무엇인지 정확히 알아보자.
머신 러닝이란#
어떤 컴퓨터 프로그램이 경험을 쌓을 수록 성능이 좋아질 때, 우리는 그 프로그램이 ‘학습’한다고 말한다. 배를 누르면 소리를 내는 인형을 생각해보자. 인형은 배가 몇번 눌리든 정해진 소리만을 낼 수 있다. 이것이 전통적인 프로그램의 예이다. 전통적인 컴퓨터 프로그램은 정해진 규칙만을 따르기 때문에 경험을 많이 한다고 성능이 더 좋아지거나 나빠지지 않는다. 반대로 페이스북은 쓰면 쓸수록 점점 더 자신의 취향에 맞는 글들을 상단에 보여준다. 이는 페이스북이 머신 러닝 기법들을 적용하고 있기 때문이다.
머신 러닝의 일반적인 정의는 다음과 같다.
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at task in T, as meausred by P, improves with experience E.
Tom Mitchell (1998)
정의만 읽어서는 머신 러닝이 정확히 무엇인지 와닿기 쉽지 않다. 머신 러닝의 개념을 좀 더 이해하기 위해서, 머신 러닝과 헷갈릴 수 있는 다른 개념들과 머신 러닝을 비교해보자.
vs. 인공 지능#
머신 러닝은 인공 지능과 어떤 관계일까? 인공지능이란 “지능적인 행위를 할 수 있는 컴퓨터 프로그램"으로 정의된다.
Artifical intelligence : Computers and computer software that are capable of intelligent behavior.
인공 지능의 정의는 추상적이다. ‘지능적인 행위’가 무엇을 말하는지는 명확하지 않다. 덧셈과 뺄셈은 지능적인 행위일까? 그렇다면 계산기는 인공 지능일까? 지능이 무엇인가 하는 것은 철학적인 주제이다. 길을 찾아가고, 언어를 이해하고, 감정을 표현하고, 사물을 인식하는 행위들이 모두 지능적인 행위가 될 수 있다.
인공 지능은 특정한 기술이라기보다 하나의 거대한 목표라고 보아야 한다. 머신 러닝은 그 목표를 이루기 위한 하나의 방법론이다.
머신 러닝이 인공 지능으로 가는 유일한 방법론은 아니다. 규칙 기반(rule-based) 접근법도 존재한다. 규칙 기반이란 사람이 일일이 프로그램에게 어떻게 하라고 지정해주는 것을 말한다. 머신 러닝 기법이 나오기 전에는 프로그램의 규칙을 정교하게 만드는 것이 인공 지능을 구현하는 유일한 방법이었다. 충분히 정교하게 설계한다면 규칙 기반 프로그램도 유용한 인공 지능 프로그램이 될 수 있다. 예컨대, 한국어 맞춤법 검사기 중에 가장 유명한 부산대 맞춤법 검사기는 규칙 기반으로 되어 있다.
그러나 규칙 기반 프로그램은 인공 지능을 구현하는 데 여러가지 한계점을 드러냈다. 규칙 기반 프로그램은 구현하는 데 너무 큰 노력이 들고, 새로운 변화에 적응하기도 어렵다. 미묘한 차이를 모두 규칙으로 만든다는 것도 불가능한 일에 가까웠다. 이에 비해 머신 러닝은 여러 분야에서 인간과 비슷하거나 인간을 뛰어넘는 성능을 내며 지능적인 프로그램을 만들 수 있음을 입증했다. 물론 아직 완전한 인공 지능을 위해서는 갈 길이 멀지만, 머신 러닝은 인공 지능이라는 꿈에 가장 가까이 다가가 있는 방법론이다.
vs. 딥 러닝#
딥 러닝이 최근에 핫하다. 사실 딥 러닝은 머신 러닝의 한 분야다. 딥 러닝과 머신 러닝, 인공 지능의 관계를 도식화하면 인공 지능이 머신 러닝을, 머신 러닝이 딥 러닝을 포함하고 있는 모습이 된다.
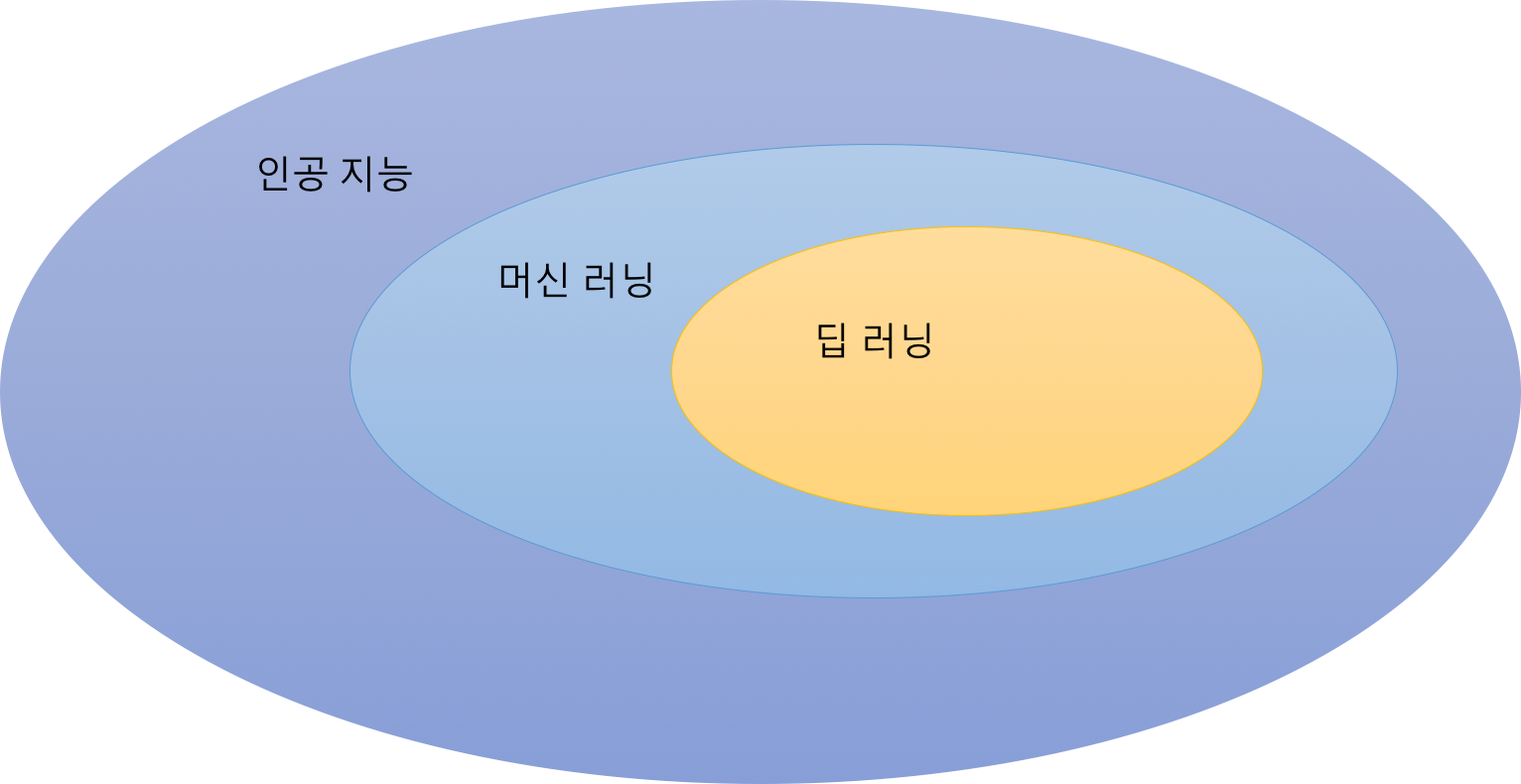
다만, 머신 러닝의 한 분야에 불과했던 딥 러닝이 최근에 너무나 급속도로 성장하면서, 이제는 때때로 ‘머신 러닝’이라는 말이 딥 러닝 이전의 전통적인 기술들을 통칭하는 말로 쓰이기도 한다. 하지만 학술적으로 머신 러닝은 딥 러닝을 포함하는 개념이다.
딥 러닝이 각광받는 데에는 몇가지 이유가 있다. 첫째로 모델의 성능이 뛰어나다. 딥 러닝은 여러 분야에서 기존의 기법들이 꿈도 꾸지 못했던 놀라운 정확도를 보여준다. 이것이 딥 러닝이 주목받는 가장 강력한 이유이다. 둘째, feature engineering이 필요 없다. 기존 머신러닝 기법들은 필수적으로 사람이 개입하여 모델에 입력할 변수를 생각해내야 했다. 하지만 딥 러닝은 모델 뿐만 아니라 모델에 들어갈 변수까지 스스로 학습하는 특징이 있다. 이를 representation learning이라고 부른다. 마지막으로 딥 러닝은 transfer learning이 용이하다. 딥 러닝에서는 하나의 문제를 잘 푸는 모델이 종종 다른 문제 역시 잘 푼다는 것이 알려져 있다. 덕분에 딥 러닝에서는 모델을 자유롭게 변형하거나 갖다 붙이기가 쉽다.
그래도 딥러닝이 아닌 기존 머신 러닝 기법들을 써야 하는 경우는 언제일까? 첫째, 모델이 ‘왜’ 그렇게 작동하는지 알아야 하는 때이다. 딥 러닝을 쓰면 많은 경우 결과는 잘 나오지만 모델이 어떻게 그 결과를 내는지는 알기 어렵다. 이런 모델을 black box 모델이라고 부른다. 딥 러닝은 속을 들여다 볼 수 없기 때문에 결과에 대한 설명이 필요한 경우에는 적합하지 않다. 예컨대, 환자의 데이터를 보고 이 환자에게 어떤 처방이 필요한지 예측했더라도 왜 그런 처방을 내렸는지 설명하지 못한다면 의사와 환자는 받아들이지 못할 것이다.
둘째, 데이터가 너무 적은 경우에는 딥 러닝을 적용하기 어렵다. 딥 러닝 모델을 학습시키기 위해서는 수많은 데이터가 필요하다. 필요한 데이터의 양은 물론 문제에 따라 다르지만, 딥 러닝 모델이 처음 유명해진 ImageNet 대회의 경우 이미지를 인식하기 위해 1000만 개가 넘는 사진 데이터가 주어진다.
셋째, 딥 러닝은 느리다. 가벼운 모델이 필요한 경우 딥 러닝은 적합하지 않다. 딥 러닝을 학습시키기 위해서 흔히 GPU(Graphical Processing Unit)를 쓰는 이유도 엄청난 계산량을 감당하기 위해서이다. 웬만한 크기의 딥 러닝 모델을 학습하기 위해서는 웬만한 GPU로 보통 1~3일이 필요하다고 한다. 빠르게 학습하고 동작하는 모델이 필요하다면 딥 러닝과는 거리가 멀다.
그밖에 딥 러닝을 쓰지 않는 경우는 기존에 충분히 검증된 모델이 있거나, 문제가 쉬워서 기존 머신 러닝 기법만으로 충분한 성능을 낼 수 있는 경우 등이 있다.
딥 러닝을 굳이 쓰지 않는 분야의 예로 한국어 형태소 분석기를 들 수 있다. 한국어 형태소 분석기는 아직까지도 대부분 전통적인 머신 러닝과 규칙 기반에 의존하고 있다. 딥 러닝을 적용한 형태소 분석기가 기존 모델에 비해 성능 향상은 미미한 수준이고 모델이 너무 느려지는 단점이 있었기 때문이다.
그러나 딥 러닝은 계속 발전 중이다. 현재 딥 러닝이 갖고 있는 문제점들이 시간이 지나면서 해결될 가능성도 배제할 수 없다. 계속해서 기술의 변화에 예의주시하는 태도가 필요하다.
vs. 통계학#
머신 러닝과 통계학은 많은 면에서 비슷하다. 통계도 데이터가 많아짐에 따라 예측의 정확도가 올라간다는 점에서 머신 러닝과 같다. 또한 머신 러닝의 많은 기법들은 통계학의 기법들과 상당히 유사하다. 예컨대, 선형 회귀는 통계학의 기법이면서 동시에 머신 러닝의 한 모델이다. 머신 러닝과 통계학은 서로 다른 영역에서 발전해왔고, 그래서 같은 개념이더라도 서로 용어가 다른 경우가 많다.
머신 러닝과 통계학의 차이는 미묘하다. 그 차이는 주로 연구의 초점과 관심사에서 나온다. 통계학은 좀 더 수학적이고 연역적이다. 이에 비해 머신 러닝 연구자들은 증명이 없더라도 새로운 접근 방식을 더 많이 시도하는 경향이 있다.
또한, 통계학은 전형적으로 작은 데이터셋을 다룬다. 하지만 머신 러닝은 빅 데이터에 더 적합하다. 통계학과 머신 러닝의 차이를 이해하는 방법 중 하나는 두 분야가 어떤 문제를 풀려고 하는지 이해하는 것이다. 통계학의 고민은 데이터가 너무 적은 것이다. 그래서 통계학은 적은 데이터에서도 의미를 끌어내기 위해 수학적으로 점점 더 정교한 방법론을 추구한다. 반대로 머신 러닝의 고민은 데이터가 너무 많은 것이다. 데이터가 너무 많으면 데이터를 저장하고 분석하는 것이 힘들어진다. 이를 분산 처리 등의 엔지니어링적인 방법으로 해결할 수도 있지만, 알고리즘 측면에서도 단순하지만 효과적인 알고리즘을 추구하게 된다.
컴퓨터 과학에서의 머신 러닝과 통계학에서의 통계적 학습 이론(statistical learning)은 각자 독자적으로 발전하면서 또 서로 영향을 주고 받는 관계에 있다. 머신 러닝에서 풀리지 않던 문제를 통계학의 이론을 가져와서 풀거나, 통계학에서 어려웠던 문제를 머신 러닝의 기법을 이용해서 해결하는 경우도 있다. 머신 러닝과 통계학의 차이는 마치 같은 의자를 옆에서 볼 때와 위에서 볼 때 모양이 다른 것과 비슷하다. 같은 개념을 다른 각도로 바라보기 때문에, 머신 러닝과 통계학 모두 공부하면 하나의 모델이라도 다각도로 이해할 수 있을 것이다.
머신 러닝 프로젝트 진행 과정 (Workflow)#
이제 머신 러닝이 무엇인지는 알았으니, 머신 러닝 프로젝트가 어떻게 진행되는지 알아보자. 물론 프로젝트에 따라 진행 과정은 조금씩 다르지만, 일반적인 예측 모델링 프로젝트(predictive modeling)는 다음과 같은 프로세스를 따른다.

데이터 수집 (Data Collection)#
요리를 하기 위해 식재료가 필요하듯이, 데이터 프로젝트를 하기 위해서는 데이터가 필요하다. 데이터를 수집하는 방법은 여러 가지다. 웹 사이트에 있는 자료들을 긁어오기 위해서는 웹 크롤링(web crawling)을 할 수도 있고. 자신이 운영하는 서비스에서 유저들의 행동 데이터를 수집하기 위해서는 로그를 남길 수도 있다. 또는 이미 데이터베이스에 데이터가 쌓여 있는 경우에 데이터 수집 과정은 간단하게 데이터베이스나 데이터 파일에서 데이터를 불러오는 것으로 충분할 수도 있다.
데이터 전처리 (Data Preprocessing)#
수집된 날 것 그대로의 데이터는 많은 경우에 더럽다. 데이터가 더럽다는 것은, 데이터에 빠진 부분(결측값)이 있거나, 중복으로 들어간 데이터 있거나, 이상한 값이 들어가 있는 경우 등등을 뜻한다. 이렇게 더러운 데이터를 정제해서 머신 러닝 모델의 입력에 적합한 형태로 바꿔주는 단계를 데이터 정제(data cleaning)이라고 부른다.
또한, 데이터에서 기존 속성(feature)을 조합해서 새로운 속성을 만들어내기 위해 데이터 전처리가 필요한 경우도 있다. 예컨대, 집의 가격을 예측하는 모델을 만든다고 하자. 주어진 데이터는 집의 가로 길이와 세로 길이이다. 하지만 집의 가격을 예측할 때는 집의 가로나 세로 길이가 아니라 면적이 더 중요한 변수일 것이다. 이 때 집의 가로 길이와 세로 길이를 곱해서 집의 면적이란 새로운 속성을 만드는 것이 필요하다. 이렇게 데이터를 가공해서 새로운 속성을 만들어내는 일을 속성 엔지니어링(feature engineering)이라고 부른다.
데이터를 정제하고 가공하는 일 외에 데이터의 스케일을 맞춰주고(feature scaling), 더미화하고(dummification), 차원을 줄이는 일(dimensionality reduction) 등을 모두 데이터 전처리라고 부르기도 한다.
탐색적 데이터 분석 (EDA: Exploratory Data Analysis)#
데이터 프로젝트의 성공 여부는 데이터 분석가가 얼마나 데이터를 이해하고 있느냐에 좌우된다. 손에 주어진 데이터를 이해하기 위해 데이터의 특징을 찾고, 숨겨진 패턴을 발견하는 과정을 탐색적 데이터 분석이라고 부른다. 구체적으로 탐색적 데이터 분석은 데이터의 히스토그램을 그려보고, 두 변수 사이의 산포도를 그려보고, 변수들의 상관관계를 보는 일 등을 포함한다.
탐색적 데이터 분석, 데이터 전처리, 모델 선택
탐색적 데이터 분석과 데이터 전처리, 모델 선택 과정은 순차적이라기 보다 반복적인 관계이다. 탐색적 데이터 분석을 통해 어떤 전처리가 필요한지 알 수 있고, 전처리를 한 후에 데이터를 더욱 잘 이해할 수도 있다. 예컨대, 데이터를 탐색하던 중에 예전에 몰랐던 이상치(outlier)을 발견할 수 있고, 이상치를 제거하는 전처리를 한 후에 데이터 탐샛을 더욱 원활하게 할 수 있다. 모델 선택 과정 역시 데이터 탐색과 밀접한 관계가 있다. 데이터를 이해하고 나서 데이터에 적합한 모델을 선택할 수 있고, 원하는 만큼 모델의 정확도가 나오지 않을 경우 그 이유를 찾기 위해 데이터 탐색 과정으로 돌아올 수도 있는 것이다.
모델 선택 (Model Selection)#
예측 모델링 프로젝트에서 모델(Model)이란 새로운 입력 데이터를 받았을 때 예측값을 계산하는 방법이다. 집값 예측 문제를 예로 들면, 집의 면적, 방의 갯수, 층수 등을 갖고 그 집의 집값을 계산하는 알고리즘이 집값 예측 모델이 된다. 세상에는 수많은 종류의 모델이 있고, 주어진 문제와 데이터에 맞는 적절한 모델을 선택하는 것은 데이터 분석가의 몫이다.
무엇을 선택할 것인가
모델을 선택한다는 것은 무엇을 선택한다는 것일까? 첫째, 말그대로 예측값을 계산하는 알고리즘을 선택한다는 것이다. 버섯의 속성들로 그 버섯이 독버섯인지 먹을 수 있는 버섯인지 분류하는 문제를 풀 때에도 로지스틱 회귀(logistic regression)부터 KNN(K-Nearest Neighbors), SVM(Support Vector Machine), 딥 러닝(deep learning)까지 수많은 방법이 있다.
둘째, 모델이 사용할 속성들(features)을 선택한다는 것이다. 때때로 의미 없는 속성이 모델에 들어갈 때 모델의 성능이 더 떨어지는 경우가 있다. 모델에 중요한 속성들을 골라내는 일도 모델 선택 과정에서 필요한 일이다.
셋째, 모델에는 일종의 모델을 조절하는 버튼인 하이퍼파라미터(hyperparameter)가 있다. 같은 모델이더라도 하이퍼파라미터에 따라서 성능이 천차만별이다. 적절한 하이퍼파라미터를 선택하는 것도 분석가의 몫이다.
평가 및 적용 (Evaluation & Application)#
평가 및 적용 단계는 만들어진 머신 러닝 모델의 성능을 평가하고, 모델을 활용하여 새로운 데이터에 대한 예측을 하는 단계이다.
머신 러닝 프로젝트에서 가장 중요하지만 가장 실수가 자주 일어나는 과정이 바로 이 평가 과정이다. 모델 평가에서 반드시 지켜야 하는 점은 평가용 데이터셋은 모델 선택과 모델 학습 과정에서 쓰이지 않아야 한다는 점이다. 즉, 프로젝트를 시작하기 전에 학습용 데이터셋과 평가용 데이터셋을 나누어놓고, 평가용 데이터셋은 모델 선택 과정이 끝나기 전까지 보지 말아야 한다는 것이다.
이렇게 하는 이유는 평가 과정의 목적이 모델이 새로운 데이터에 대해 얼마나 일반화 (generalization) 가능한지 측정하는 것이기 때문이다. 모델이 아직 보지 못한 새로운 데이터에 얼마나 잘 작동하는지 제대로 측정하기 위해서는, 평가용 데이터셋은 모델이 ‘아직 보지 못한 새로운 데이터’이어야 한다. 그렇기 때문에 평가용 데이터셋을 미리 떼어놓고 일부러 모델을 만드는 과정에서 제외하는 것이다.
Conclusion#
데이터 과학은 흥미로운 분야이고, 그 중에서 머신 러닝은 데이터 과학의 핵심적인 부분이다. 나무 하나하나를 보기 전에 숲을 보는 것이 중요하듯이, 이 글에서는 머신 러닝이란 무엇이고 전체적인 데이터 분석 과정이 어떻게 이루어지는지 데이터 과학의 숲을 한번 훑어보았다. 이 글이 데이터 과학을 처음 시작하는 사람 뿐만 아니라, 데이터 과학에 익숙한 사람들에게도 숲을 보는 것을 잊지 않게 함으로써 도움이 되었으면 하는 바람이다.