쉽게 씌어진 word2vec
텍스트 기반의 모델 만들기는 텍스트를 숫자로 바꾸려는 노력의 연속이다. 텍스트를 숫자로 바꾸어야만 알고리즘에 넣고 계산을 한 후 결과값을 낼 수 있기 때문이다.
텍스트를 숫자로 바꾸는 일 중의 하나로 단어를 벡터로 바꾸는 일을 생각할 수 있다. 단어를 벡터로 바꾸는 가장 단순한 방법은 단어에 번호를 매기고, 그 번호에 해당하는 요소만 1이고 나머지는 0을 갖는 벡터로 바꾸는 것이다. 예를 들어 총 5개의 단어가 있는데 ‘강아지’라는 단어에 2번을 매겼다고 하자. 그러면 ‘강아지’는 2번째 요소만 1이고 나머지는 모두 0인 5차원의 벡터로 표현이 된다. 이렇게 단어를 벡터로 바꾸는 방식을 one-hot encoding이라고 부른다. N개의 단어가 있다면 각 단어는 한 개의 요소만 1인 N차원의 벡터로 표현된다.
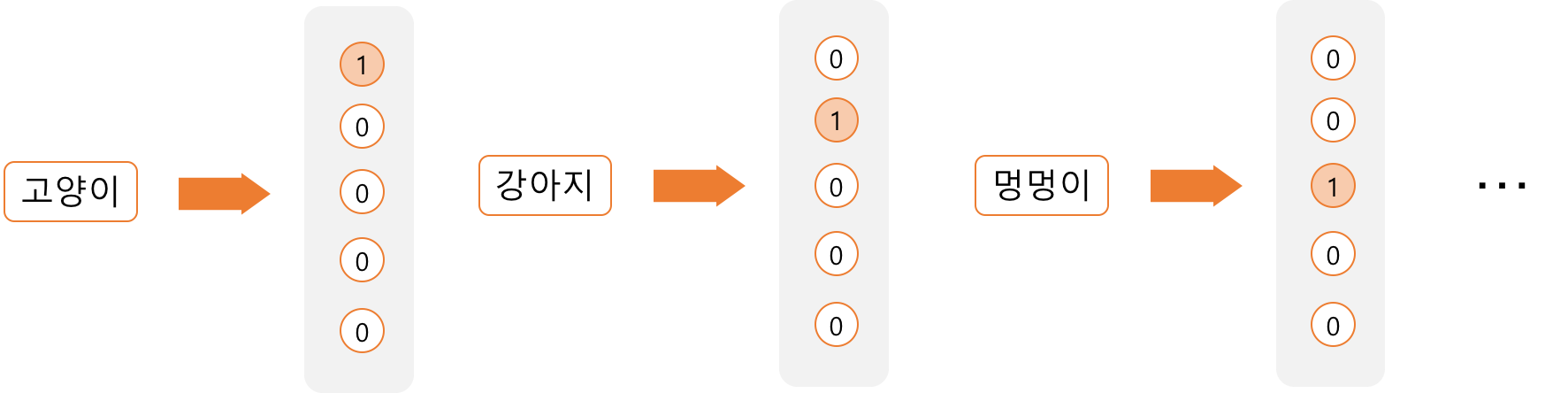
One-hot encoding의 단점은 벡터 표현에 단어와 단어 간의 관계가 전혀 드러나지 않는다는 점이다. ‘강아지’와 ‘멍멍이’라는 두 단어가 있을 때 이 두 단어는 의미가 비슷한데도 불구하고 전혀 다른 벡터로 표현이 된다. ‘강아지’와 ‘멍멍이’의 관계가 ‘강아지’와 ‘자유주의’ 간의 관계와 차이가 없는 것이다. One-hot encoding은 어떤 단어가 유사한 의미를 갖고 어떤 단어가 반대의 의미를 갖는지 등 단어 간의 관계는 전혀 반영하지 못한다.
단어를 벡터로 바꿀 때, 좀 더 똑똑하게 바꿔서 벡터에 단어의 의미를 담을 수 있다면 어떨까? 비슷한 의미의 단어들은 비슷한 벡터로 표현이 된다면? 더 나아가 단어와 단어 간의 관계가 벡터를 통해서 드러날 수 있다면? 예를 들면 ‘왕’과 ‘여왕’의 관계가 ‘남자’와 ‘여자’의 관계라는 것을 벡터를 통해 알아낼 수 있다면, 유용하게 쓸 수 있을 것이다.
이렇게 단어를 벡터로 바꾸는 모델을 단어 임베딩 모델(word embedding model)이라고 부른다. word2vec은 단어 임베딩 모델들 중 대표적인 모델이다. 이 글에서는 단어 임베딩 모델의 기본 아이디어와 word2vec의 작동 원리에 대해 알아본다.
단어 임베딩(Word Embedding) 맛보기#
아래 웹사이트는 Word2Vec 알고리즘을 우리말에 적용해 본 사이트이다.
위의 웹사이트에 들어가 “한국 - 서울 + 도쿄"를 해보자. 무엇이 나올까? “한국 - 제주도 + 대마도"는 어떨까? 용기 있는 사람은 “김정은 - 북한 + 한국"도 해보자.
벡터 간에는 덧셈 뺄셈을 할 수 있다. 위의 예시는 벡터 간의 덧셈 뺄셈이 해당하는 단어 간의 의미의 합과 의미의 차로 반영이 된다는 것을 보여준다. 즉, 단어를 벡터로 바꿀 때 단어의 의미가 벡터에 잘 담긴 것이다.
단어의 의미를 최대한 담는 벡터를 만들려는 알고리즘이 단어 임베딩 모델이다. 현대적인 자연어 처리 기법들은 대부분 이 임베딩 모델에 기반을 두고 있다. 그렇다면 어떻게 벡터에 단어의 의미를 담을 수 있을까?
Sparse vs. Dense Representations#
잠시 데이터가 무엇인지에 대해 다시 생각해보자. 데이터는 대상의 속성을 표현해놓은 자료이다. 우리는 어떤 대상이든 대상의 속성들을 표현하고, 그것을 바탕으로 모델을 만든다. 예를 들어 버섯을 조사해 놓은 데이터가 있다면 이것은 버섯이라는 ‘대상’을 색깔, 크기 같은 ‘속성’들로 표현한 것이고, 이 정보를 바탕으로 그 버섯이 독버섯인지 아닌지 판별하는 모델을 만들 수 있다. 자연히 대상을 어떤 속성으로 표현하는지는 모델의 성능에 매우 중요하다. 이렇게 대상의 속성을 표현하는 방식을 feature representation이라고 부른다.
자연어 처리의 경우 대상은 텍스트이고, 이 텍스트의 속성을 표현해놓은 것이 데이터가 된다. 대상을 단어로 좁혀보면, 단어에는 어떤 속성이 있을까? 일단 단어 그 자체가 있다. 예를 들어 해당 단어가 ‘강아지’라면 그 단어가 ‘강아지’라는 것 자체가 이 대상의 속성이 된다. 또한 이 단어의 품사가 중요한 속성일 수도 있다. 앞 단어가 무엇인지 또는 문장에서 몇번째 단어인지가 중요할 수도 있다. 풀려는 문제에 따라서는 단어 자체가 긴지 짧은지가 중요할 수도 있다. 이런 언어적 정보(linguistic information)를 추출해서 표현하는 것이 언어의 feature representation이다.
이런 속성들을 어떻게 표현할까? 언어의 속성을 표현하는 방법으로 크게 sparse representation과 dense representation이라는 두가지 방식이 있다. sparse representation은 위에서 언급했던 one-hot encoding을 뜻하고, dense representation은 word2vec의 방법을 뜻한다. 이 두개를 비교함으로써 word2vec의 특징을 좀 더 잘 이해할 수 있다.
Sparse representation#
Sparse representation, 즉 one-hot encoding은 해당 속성이 가질 수 있는 모든 경우의 수를 각각의 독립적인 차원으로 표현한다. 예를 들어, 해당 단어가 ‘강아지’라는 속성을 표현해보자. 우리가 가진 단어가 총 N개라면 이 속성이 가질 수 있는 경우의 수는 총 N개이다. One-hot encoding에서는 이 속성을 표현하기 위해 N차원의 벡터를 만든다. 그리고 ‘강아지’에 해당하는 요소만 1이고 나머지는 모두 0으로 둔다. 이런 식으로 단어가 가질 수 있는 N개의 모든 경우의 수를 표현할 수 있다.
마찬가지 방식으로 품사가 ‘명사’라는 속성을 표현하고 싶다면 품사의 개수만큼의 차원을 갖는 벡터를 만들고, ‘명사’에 해당하는 요소만 1로 두고 나머지는 모두 0으로 둔다. 다른 속성들도 모두 이런 방식으로 표현할 수 있다.
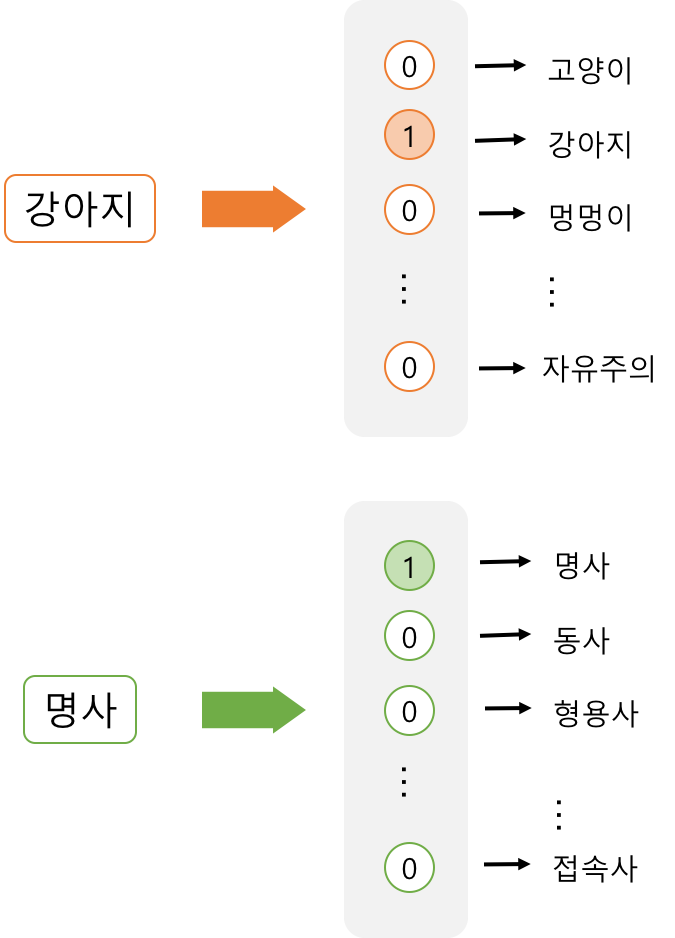
이렇게 one-hot encoding으로 만들어진 표현을 sparse representation이라고도 부른다. 벡터나 행렬이 sparse하다는 것은 벡터나 행렬의 값 중 대부분이 0이고 몇몇 개만 값을 갖고 있다는 것을 뜻한다. one-hot encoding으로 만들어진 벡터는 0이 대부분이기 때문에, sparse한 벡터가 되는 것이다.
Sparse representation은 가장 단순하고 전통적으로 자주 쓰이던 표현 방식이다.
Dense representation#
Dense representation은 각각의 속성을 독립적인 차원으로 나타내지 않는다. 대신, 우리가 정한 개수의 차원으로 대상을 대응시켜서 표현한다. 예컨대 해당 속성을 5차원으로 표현할 것이라고 정하면 그 속성을 5차원 벡터에 대응시키는 것이다. 이 대응을 임베딩(embedding)이라고 하며, 임베딩하는 방식은 머신 러닝을 통해 학습하게 된다.
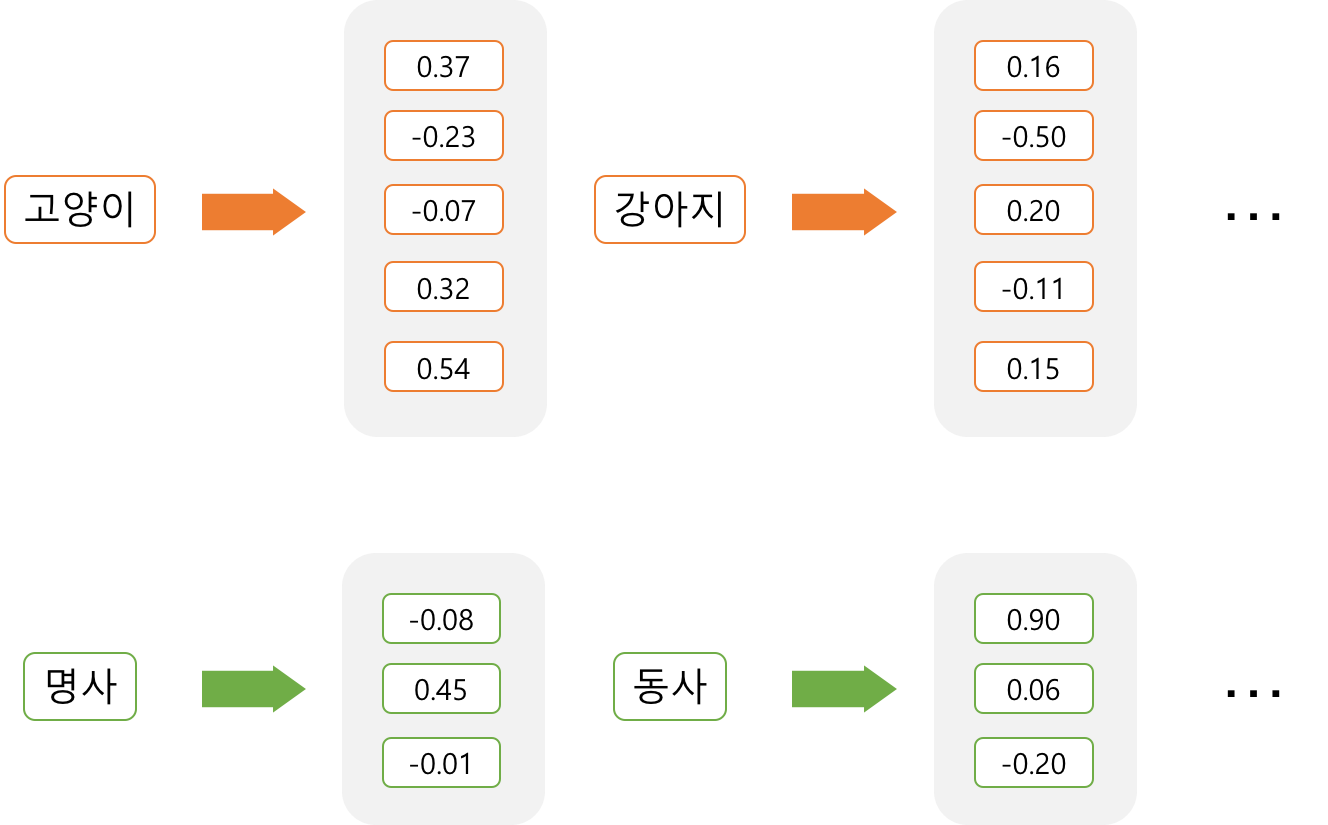
임베딩된 벡터는 더이상 sparse하지 않다. One-hot encoding처럼 대부분이 0인 벡터가 아니라, 모든 차원이 값을 갖고 있는 벡터로 표현이 된다. 그래서 sparse의 반대말인 dense를 써서 dense representation 표현이라고 부른다.
Dense representation은 또다른 말로 distributed representation이라고도 불린다. ‘Distributed’라는 말이 붙는 이유는 하나의 정보가 여러 차원에 분산되어 표현되기 때문이다. Sparse representation에서는 각각의 차원이 각각의 독립적인 정보를 갖고 있지만, Dense representation에서는 하나의 차원이 여러 속성들이 버무려진 정보를 들고 있다. 즉, 하나의 차원이 하나의 속성을 명시적으로 표현하는 것이 아니라 여러 차원들이 조합되어 나타내고자 하는 속성들을 표현하는 것이다.
위 그림에서 ‘강아지’란 단어는 [0.16, -0.50, 0.20. -0.11, 0.15]라는 5차원 벡터로 표현된다. 이 때 각각의 차원이 어떤 의미를 갖는지는 알 수 없다. 여러 속성이 버무러져서 표현되었기 때문이다. 다만 ‘강아지’를 표현하는 벡터가 ‘멍멍이’를 표현하는 벡터와 얼마나 비슷한지, 또는 ‘의자’를 표현하는 벡터와는 얼마나 다른지는 벡터 간의 거리를 통해 알 수 있다. 이러한 관계에서 단어 벡터의 의미가 드러난다.
단어 벡터의 값들은 머신 러닝을 통해 학습된다. 뒤에 나올 word2vec은 이 값들을 학습하는 방법론 중의 하나이다.
Dense Representation의 장점#
이제 dense representation이라는 방식으로 대상을 표현할 수 있다는 것을 알았다. 그렇다면 sparse representation에 비해 dense representation의 장점은 무엇일까?
첫번째, dense representation은 적은 차원으로 대상을 표현할 수 있다는 장점이 있다. sparse representation으로 대상을 표현하면 보통 차원 수가 엄청나게 높아진다. 일상적인 텍스트에서 쓰이는 단어의 개수는 몇 천개에 이른다. 이 단어들을 sparse representation으로 표현하려면 몇 천 차원이 필요하다. 게다가 이렇게 만들어진 벡터들은 대부분의 값이 0을 갖는다.
입력 데이터의 차원이 높으면 차원의 저주(curse of dimensionality)라는 문제가 생긴다. 입력 데이터에 0이 너무 많으면 데이터에서 정보를 뽑아내기 어려워진다. 따라서 sparse representation을 쓰면 모델의 학습이 어렵고 성능이 떨어지기 쉽다.
Dense representation으로 단어를 표현할 때는 보통 20 ~ 200차원 정도를 사용한다. Sparse representation에서 몇 천 차원이 필요했던 것에 비해 훨씬 적은 차원이다. 게다가 0이 거의 없고 각각의 차원들이 모두 정보를 들고 있으므로 모델이 더 작동하기 쉬워지는 것이다.
두번째, dense representation은 더 큰 일반화 능력(generalization power)을 갖고 있다. 예를 들어 ‘강아지’라는 단어가 우리가 가진 학습 데이터셋에 자주 나왔고 ‘멍멍이’라는 단어는 별로 나오지 않았다고 생각해보자. sparse representation에는 ‘강아지’와 ‘멍멍이’ 간의 관계가 전혀 표현되지 않는다. 그 때문에 모델이 ‘강아지’에 대해 잘 알게 되더라도 ‘멍멍이’에 대해 더 잘 알게 되는 것은 아니다. 모델이 ‘강아지’가 ‘개’의 아기 상태라는 것을 알게 되었더라도, ‘멍멍이’가 ‘개’와 어떤 관계인지는 여전히 모르는 것이다.
그러나 dense representation에서 ‘강아지’와 ‘멍멍이’가 서로 비슷한 벡터로 표현이 된다면, ‘강아지’에 대한 정보가 ‘멍멍이’에도 일반화될 수 있다. 예컨대 ‘강아지’라는 단어를 입력으로 받고 ‘애완동물’이라는 출력을 하도록 모델이 학습이 된다면, ‘멍멍이’도 비슷한 입력이기 때문에 비슷한 출력이 나올 가능성이 높다. 즉, ‘강아지’라는 단어에 대해 배운 지식을 ‘멍멍이’라는 단어에도 적용할 수 있는 것이다.
word2vec#
물론 지금까지 언급한 dense representation의 장점들은 모두 단어 임베딩(word embedding)이 잘 학습되었다는 전제 하에서 성립한다. 그렇다면 단어 임베딩을 어떻게 학습할 수 있을까?
단어 임베딩을 학습하는 알고리즘에는 여러가지가 있다. 그 중 가장 자주 쓰이고 가장 유명한 방식은 word2vec이다. 또다른 방식으로는 GloVe, FastText 등이 있다. 여기서는 word2vec이라는 모델에 대해서만 알아본다.
아이디어#
word2vec은 단어를 표현하는 방법을 어떻게 학습하는 것일까? word2vec의 핵심적인 아이디어는 이것이다.
친구를 보면 그 사람을 안다.
또는
단어의 주변을 보면 그 단어를 안다. You shall know a word by the company it keeps. - 언어학자 J.R. Firth (1957)
잠시 퀴즈를 하나 풀어보자. 다음 빈칸에 들어갈 수 있는 단어는 무엇이 있을까?
italian, mexican 등의 단어를 떠올릴 수 있다. 하지만 chair, parking 이런 말들은 들어가기 어려울 것이다.
단어의 주위만 보았는데도 어떤 단어가 적합하고 어떤 단어가 부적합한지가 어느정도 드러난다. 이 빈칸에 들어갈 수 있는 단어들은 서로 비슷한 맥락을 갖는 단어들, 즉 서로 비슷한 단어들이다. 단어의 주변을 보면 그 단어를 알 수 있기 때문에, 단어의 주변이 비슷하면 비슷한 단어라는 말이 된다.
비슷한 맥락을 갖는 단어에 비슷한 벡터를 주고 싶다면 어떻게 할 수 있을까? 여러 방법이 있지만 그중에 word2vec은 predictive method라는 방식에 속한다. predictive method란 맥락으로 단어를 예측하거나 단어로 맥락을 예측하는 문제를 마치 지도 학습(supervised learning)처럼 푸는 것이다. 이 예측 모델을 학습하면서 단어를 어떻게 표현해야 할지를 배우게 되고, 이 과정에서 비슷한 단어가 비슷한 벡터로 표현된다.
word2vec의 알고리즘은 지도 학습을 닮았지만 사실은 비지도 학습(unsupervised learning) 알고리즘이다. 어떤 단어와 어떤 단어가 비슷한지 사람이 알려주지 않아도 word2vec은 비슷한 단어들을 찾아낼 수 있다. 비지도 학습의 장점은 정답지가 필요 없다는 것이다. 세상에 텍스트는 널려 있다. word2vec은 그 텍스트를 모두 학습 데이터로 쓸 수 있다.
알고리즘#
word2vec 안에도 두가지 방식이 있다. 하나는 맥락으로 단어를 예측하는 CBOW(continuous bag of words) 모델이다. 또다른 하나는 단어로 맥락을 예측하는 skip-gram 모델이다. 그 중에서 여기서는 CBOW 하나만 살펴보자. CBOW 모델을 반대로 뒤집으면 skip-gram 모델이 되므로, 하나만 이해하면 다른 하나는 쉽다.
CBOW 모델은 주변 단어, 다른 말로 맥락(context)으로 타겟 단어(target word)를 예측하는 문제를 푼다. 주변 단어란 보통 타겟 단어의 직전 몇 단어와 직후 몇 단어를 뜻한다. 타겟 단어의 앞 뒤에 있는 단어들을 타겟 단어의 친구들이라고 보는 것이다. 이 주변 단어의 범위를 window라고 부른다.
예를 들어 “Colorless green ideas sleep furiously"라는 문장이 있다고 해보자. 주변 단어는 타겟 단어의 앞 단어와 뒷 단어 하나씩이라고 정의하자. “green"이 타겟 단어라면 “Colorless"부터 “ideas"까지 창문이 놓여있다고 생각하고 이 단어들만 보는 것이 window 접근법이다.
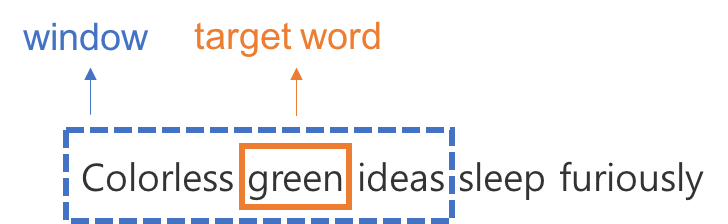
앞과 뒤에서 몇 단어까지 볼지는 지정해줄 수 있다. 이를 window size라고 한다.
데이터셋을 만들 때 word2vec은 sliding window라는 방법을 쓴다. green을 타겟 단어로 놓고 Colorless부터 ideas까지 한번 본 다음에 window를 밀어서 이번에는 ideas를 중심에 놓는다. 그 다음은 sleep을 중심에 놓고 본다. 이렇게 window를 점차 옆으로 밀면서 타겟 단어를 계속 바꾸는 방식을 sliding window라고 부른다. 만들어진 window 하나 하나가 우리의 학습 데이터가 된다.

CBOW는 맥락으로 단어를 예측하는 문제를 푼다. 즉, 주위에 있는 단어가 입력이 되고 타겟 단어가 우리가 예측해야 하는 출력값이 되는 문제를 푸는 것이다. 그 과정에서 모델의 파라미터를 학습하고, 이렇게 학습된 파라미터가 단어들의 벡터 표현이 된다.
파라미터가 학습되는 방식은 일반적인 머신 러닝, 딥 러닝 모델이 학습되는 방식과 같다. 처음 파라미터는 랜덤으로 초기화된 상태(random initialization)로 시작한다. 이 파라미터로 예측을 하고, 실제 값과 차이가 생기면 틀린 만큼 파라미터들을 조금씩 조정한다. 이 과정을 학습 데이터셋을 돌아가며 반복한다. 뉴럴 네트워크 용어로는 이를 backpropagation이라고 부르며, 그 원리는 gradient descent와 같다. 즉 cost function이 최소화되는 쪽으로 파라미터들을 업데이트해 가는 것이다.
CBOW에서 모델의 입력은 주변 단어이다. 그런데 입력이 비슷하면 어떻게 될까? 출력도 비슷해질 것이다. 즉 주위에 있는 단어가 비슷하면 그 단어의 벡터 표현 역시 비슷해진다. 벡터가 비슷하다는 말은 벡터 간의 거리가 짧다는 말이다. word2vec은 이러한 방식으로 비슷한 맥락의 단어에 비슷한 벡터를 준다.
수학적으로 이해하기#
글로 된 설명을 모호하게 느끼는 사람들을 위해 수학적으로 word2vec을 풀어보자. 여기서는 가장 간단한 형태의 CBOW, 즉 문맥에서 한 단어만 보고 타겟 단어를 예측하는 문제를 생각해보자. 한 단어가 앞 단어인지 뒷 단어인지는 중요하지 않지만, 편의상 앞 단어라고 하자. 입력으로 타겟 단어의 앞 단어가 들어가고 출력으로 타겟 단어가 나와야 하는 문제이다.
아래 그림은 이 단순화된 문제의 뉴럴 네트워크 모델이다. V는 사전의 크기(vocabulary size), N은 히든 레이어의 크기(hidden layer size)을 뜻한다. 사전의 크기란 다른 말로 단어의 개수이다. 히든 레이어의 크기는 우리가 단어를 몇 차원으로 임베딩할지를 나타낸다.
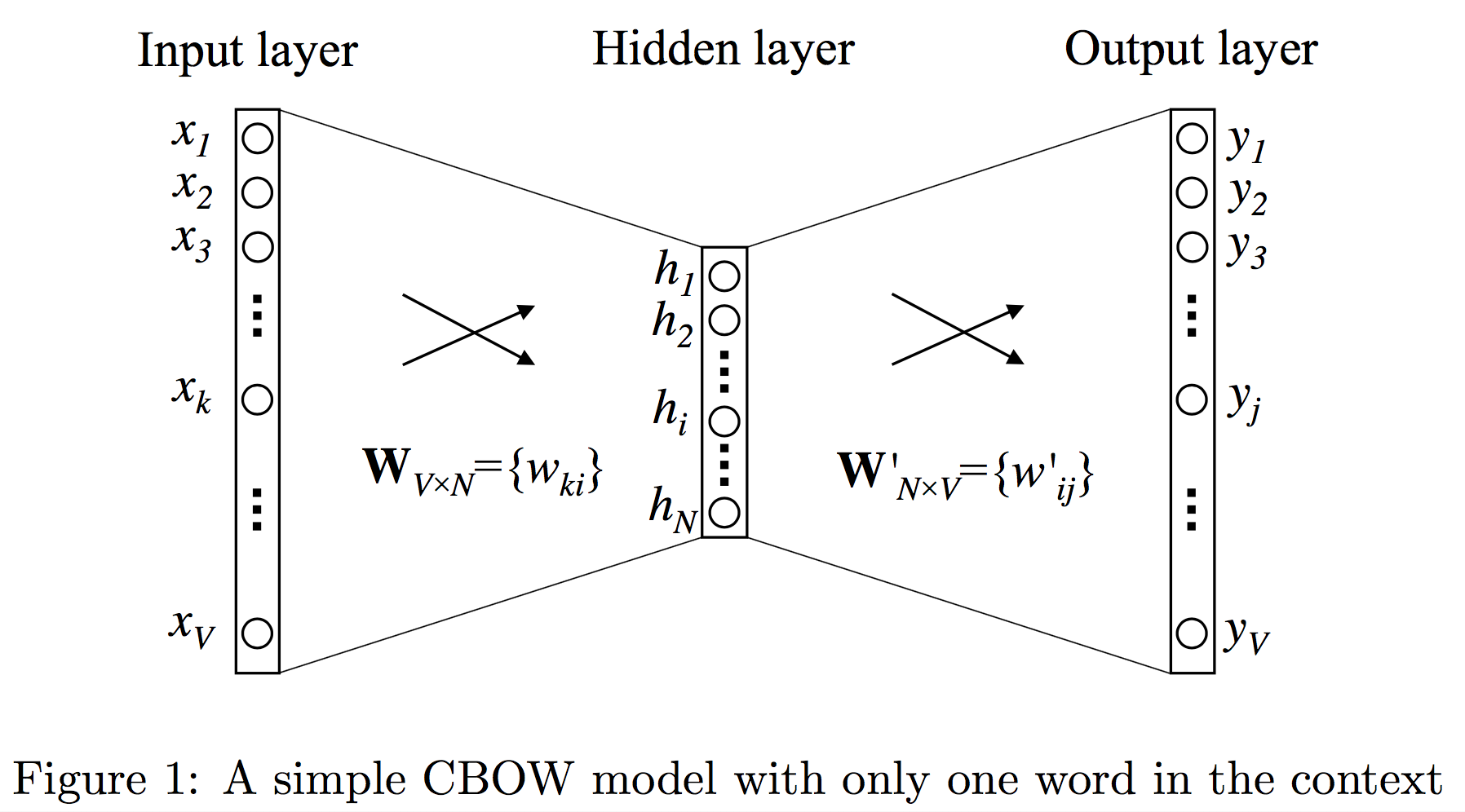
입력은 one-hot encoding된 벡터이다. 입력 단어, 즉 타겟 단어의 앞 단어는 V개의 요소 중 하나만 1이고 나머지는 모두 0인 벡터로 표현된다. 이렇게 단어의 개수만큼의 차원을 갖는 입력 레이어(input layer)가 히든 레이어(hidden layer)에서 임베딩 크기만큼의 차원의 벡터로 대응된다. 마지막으로 출력 레이어(output layer)는 다시 단어의 개수만큼의 차원을 갖는다. 출력은 타겟 단어이므로 단어의 개수만큼의 경우의 수가 있기 때문이다.
레이어들 사이의 뉴런들은 서로 모두 연결되어(fully connected) 있다. 입력 레이어(input layer)와 히든 레이어(hidden layer) 사이를 연결하는 파라미터들은 V X N의 행렬 W로 나타낼 수 있고, 입력 레이어에서 히든 레이어로 넘어가는 것은 단순히 행렬 W를 곱하는 것과 같다. x가 입력 벡터라고 하면, 히든 레이어 h는 $W^Tx$ 로 계산된다. 이 벡터는 V차원, 즉 임베딩 차원의 벡터가 된다.
입력 벡터 x는 one-hot encoding된 벡터이다. x의 요소 중 k번째 요소만 1이라고 하자. x의 나머지 요소가 모두 0이기 때문에 다른 부분은 모두 무시되고 $W^Tx$ 의 결과는 $W^T$ 의 k번째 열, 즉 W의 k번째 행만 남는다. 이 벡터가 해당 단어의 N차원 벡터 표현이 된다. W의 각 행들은 각각 해당하는 단어의 N차원의 벡터 표현인 것이다. W의 i번째 행을 $v^T_{w_I}$ 라고 부르면, 히든 레이어 h는 $v^T_{w_I}$와 결국 같다는 것을 알 수 있다.
$$ h = W^Tx = W^T_{(k, )} := v^T_{w_I} $$
입력 레이어에서 히든 레이어로 넘어가면서 우리는 히든 레이어 h를 얻었다. 히든 레이어에서 출력 레이어로 넘어가기 위해, 우리는 또다른 행렬 $W’$ 가 필요하다. $W’$ 는 N X V의 행렬이다. 이 파라미터 행렬을 이용해서, 우리는 모든 단어에 대해 출력 레이어의 점수 $u_j$를 계산할 수 있다. 아래 식에서 $z_{w_j}$는 $W’$의 j번쩨 열을 뜻한다. 즉 $u_j$ 는 j번째 단어에 대한 예측 점수이다.
$$ u_j = {z_{w_j}}^T h $$
마지막으로 예측 점수를 각 단어의 확률값으로 바꿔주기 위해 softmax를 쓴다. 이는 각 단어의 점수에 비례하여 점수를 확률로 만들어주는 방법이다. 이 방식을 통해 각 단어의 예측 점수가 모두 0 이상이고 모두 더하면 1이 되는 확률값으로 변한다.
$$ p(w_j|w_I) = y_j = \frac{exp(u_j)}{\sum^V_{j’ = 1}exp(u_{j’})} $$
여기에서 $y_j$ 는 출력 레이어의 j번째 출력값이다. 위 식들을 조합하면 최종적으로 아래와 같은 식을 얻는다.
$$ p(w_j|w_I) = \frac{\exp({z_{w_j}}^Tv_{w_I})}{\sum^V_{j’ = 1}\exp({z_{w_{j’}}}^Tv_{w_I})} $$
$$v′$$
결과적으로 단어 w는 두가지 벡터로 표현된다. 바로 $v_w$ 와 $z_w$ 이다. $z_w$는 입력 레이어에서 히든 레이어로 넘어가는 행렬 W에서 나오며, $z_w$는 히든 레이어에서 출력 레이어로 넘어가는 행렬 $W’$ 에서 나온다. $v_w$를 단어 w의 입력 벡터(input vector), $z_w$를 단어 w의 출력 벡터(output vector)라고도 부른다.
입력 벡터(input vector)와 출력 벡터(output vector) 모두 각각 단어의 의미를 담고 있지만, 이 둘을 조합하면 단어의 의미를 더욱 잘 표현할 수 있다고 알려져 있다.
여기에서는 word2vec의 가장 기본적인 알고리즘만을 알아보았다. 이 파라미터들이 어떻게 학습되는지, 맥락이 여러 단어일 경우에는 어떻게 일반화되는지, skip-gram은 어떻게 작동하는지, 알고리즘의 계산 속도를 높이기 위해 어떤 방법들이 쓰이는지를 알고 싶다면 word2vec Parameter Learning Explained를 참고하기 바란다.
시각화해서 이해하기#
word2vec의 원리를 시각화해서 이해해보자. 아래는 word2vec을 이해하기 쉽게 직접 학습시켜보며 시각적으로 볼 수 있는 웹페이지다.
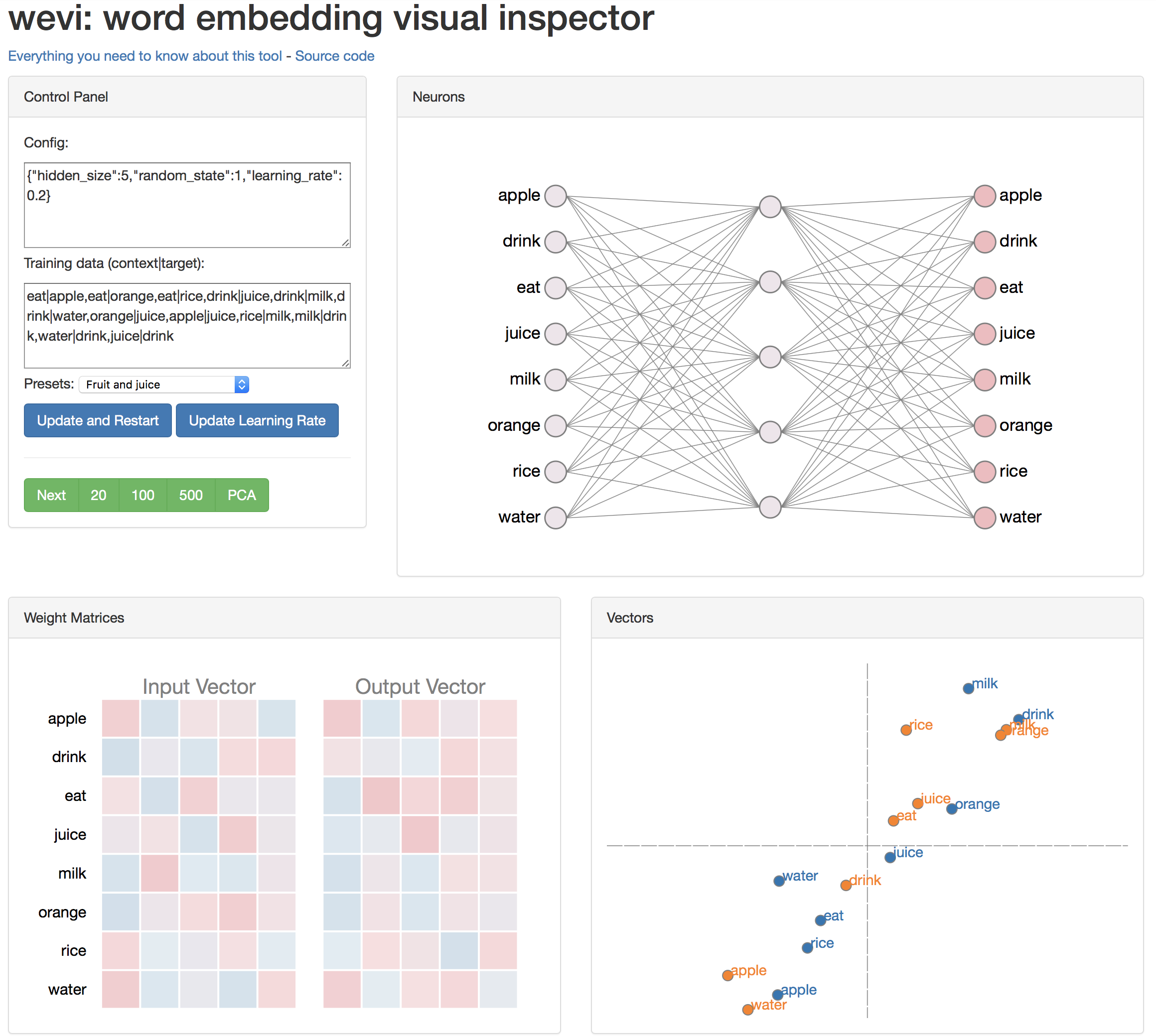
- 왼쪽 위는 이 모델의 설정과 학습 데이터셋을 보여준다. 학습 데이터셋에서
eat|apple은eat이 들어왔을 때apple을 예측하도록 학습하겠다는 뜻이다. - 오른쪽 위에는 word2vec 모델이 있다. 왼쪽 단어들이 입력 레이어(input layer)이고 오른쪽 단어들이 출력 레이어(output layer)이다. 왼쪽 단어들 중 하나가 들어왔을 때 오른쪽 단어가 어떻게 예측되는지를 보여준다.
- 왼쪽 아래는 단어 벡터의 값을 색깔로 보여준다. 정확한 숫자는 보여지지 않지만 빨간색일수록 숫자가 크다는 뜻이고 파란색일수록 숫자가 작다는 뜻이다. 이 색깔의 의미는 오른쪽 위 Neurons에도 동일하게 적용된다.
- 오른쪽 아래는 PCA를 이용해 단어 벡터를 2차원으로 표현한 것이다.
Next를 누르면 학습이 한번 진행된다. 첫번째로 eat이 들어가서 apple을 예측해야 한다. 처음에는 무작위값으로 초기화된 weights가 곱해지기 때문에 eat에서 apple을 예측할 확률이나 water 예측할 확률이나 차이가 없다. 하지만 점차 학습이 진행되면서 같이 나올만한 단어와 나오지 않을 단어들의 차이가 뚜렷해진다. 점점 좋은 벡터를 학습하게 되며 오른쪽 아래 PCA 화면에서 비슷한 단어끼리는 뭉치고, 다른 단어끼리는 떨어진다. 이렇게 학습이 되는 과정을 볼 수 있다.
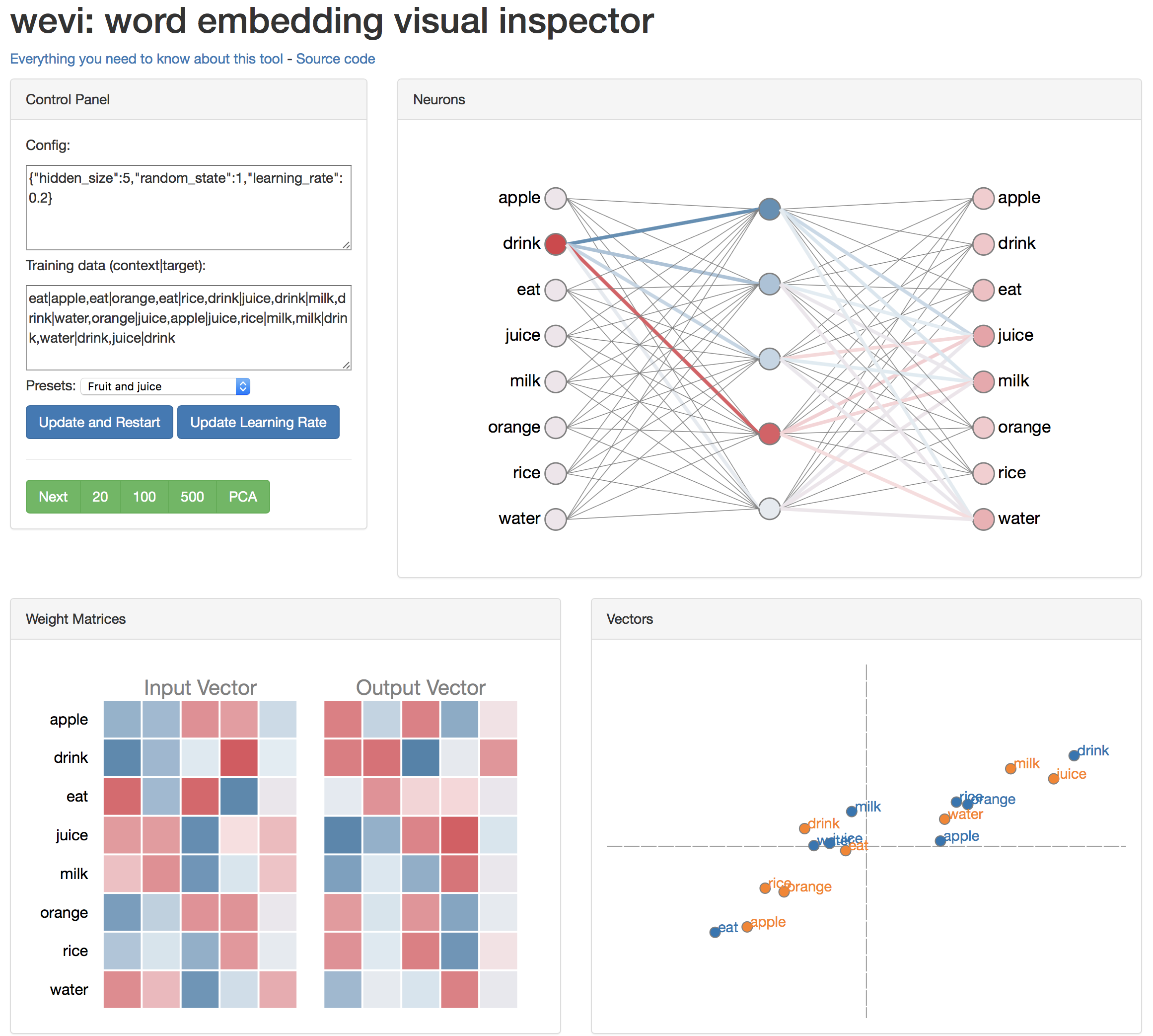
학습이 된 결과를 보면 오른쪽 아래 그래프에서 apple, orange, rice가 뭉쳤고 milk, juice, water가 뭉쳤다. 먹는 것과 마시는 것이 나눠진 것을 알 수 있다. 오른쪽 위 그래프에서는 drink라는 입력이 들어오자 juice, milk, water에 붉은색으로 높은 가중치가 부여되는 것을 알 수 있다.
실제 데이터로 만든 단어 벡터 시각화#
다음은 아마존에서 스마트폰 구매자들이 남긴 리뷰 텍스트를 바탕으로 word2vec을 이용해 만든 단어 벡터를 t-SNE라는 기법을 이용해 2차원으로 차원 축소한 뒤 인터렉티브 시각화를 해본 것이다. 아래 링크에서 그래프의 아무 점이나 점에 마우스를 올리면 어떤 단어들끼리 뭉쳤는지 직접 눈으로 확인할 수 있다. 더불어 실제 텍스트 데이터를 어떻게 가공해서 word2vec 알고리즘을 적용하는지 실습 코드까지 볼 수 있다. 아래 링크에 들어가 직접 마우스를 대보길 바란다.
참고 자료#
다음은 이 글을 쓰며 참고했던 자료 및 이 글과 함께 읽으면 좋은 글들이다.