머신러닝 모델의 블랙박스 속을 들여다보기 : LIME

머신 러닝 모델에 대해서 예측의 이유를 설명하는 것은 어렵습니다. 모델이 복잡해질수록 예측의 정확도는 올라가지만, 결과의 해석은 어려워지죠. 그렇기 때문에 많은 머신 러닝 모델들이 블랙박스라고 불립니다.
하지만 모델이 ‘왜’ 그렇게 작동하는지 아는 것은 중요합니다. 의사가 “인공 지능이 이렇게 하래요"라고 말하면서 환자를 수술하지는 않겠죠. 은행에서 의심스러운 거래를 차단하는 경우에도 차단당한 이용자는 설명을 요구할 것입니다. 하물며 Netflix에서 볼 영화를 선택할 때도, 추천 영화에 시간을 투자하기 전에 어느 정도의 모델에 대한 신뢰감은 필요합니다.
모델의 예측의 근거를 이해하는 것은 언제 모델을 신뢰할지 또는 신뢰하지 않을지 결정하는 데도 중요합니다. 아래 그림을 예를 들어볼까요. 아래 그림은 머신 러닝 모델이 특정 환자가 독감에 걸렸다고 예측하는 예입니다. 만약 예측을 하는 것만으로 끝나지 않고, ‘Explainer’가 있어서 이 예측을 내릴 때 모델에서 가장 중요했던 증상을 강조해주며 모델을 설명한다면, 아마 의사는 모델을 신뢰하거나 또는 신뢰하지 않기로 결정하기가 좀 더 쉬울 것입니다.
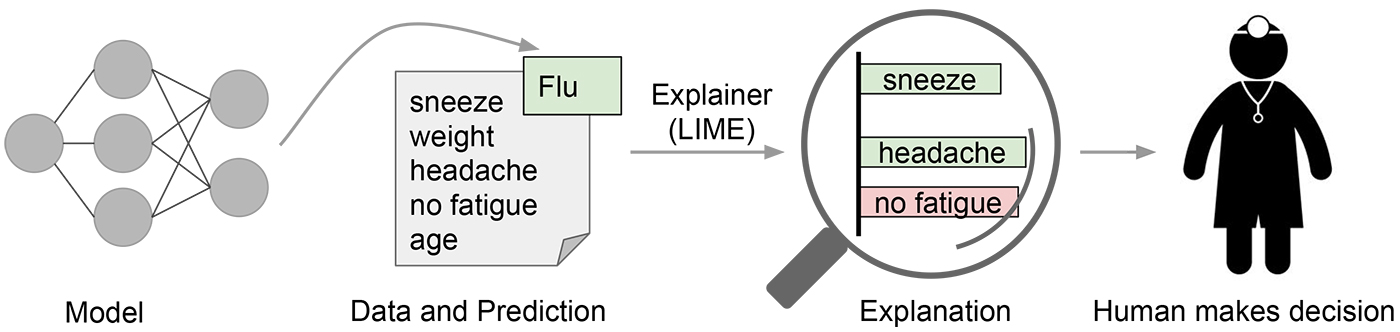
모델의 예측을 얼마나 믿을 수 있는지는 보통 평가용 데이터셋에서 구한 정확도 등으로 검증합니다. 하지만, 머신 러닝 해보신 분들이라면 다 아시듯이 현실에서 이런 수치들은 흔히 믿을 수 없을 때가 많습니다. 때로는 평가용과 학습용 데이터셋을 잘못 나누어서 평가용 데이터셋의 정보가 학습용 데이터셋에 섞여 있기도 하죠. 때로는 평가용 데이터셋이 현실을 정확하게 반영하지 않을 때도 있습니다. 이럴 때 모델의 작동 방식을 이해하는 것은 모델의 성능을 평가하는 데 유용합니다. 사람은 보통 모델이 어떻게 행동해야 한다는 직관을 갖고 있습니다. 모델의 예측의 근거를 보여주고 사람의 직관을 이용하면 정확도 등의 지표로 잡아내기 어려운 모델의 신뢰도를 평가할 수 있죠.
이번 포스팅에서는 어떤 예측 모델이든 그 모델이 ‘왜’ 그렇게 예측했는지 설명해주는 모델, LIME (Local Interpretable Model-agnostic Explanations)에 대해서 알아보겠습니다. 그리고 Python과 Jupyter Notebook에서 쉽게 LIME을 사용하는 방법을 소개해드리겠습니다.
무엇을 할 수 있나요?#
LIME은 뉴럴 네트워크, 랜덤 포레스트, SVM 등 어떤 머신 러닝 예측 모델에도 적용할 수 있습니다. 데이터 형식도 이미지, 텍스트, 수치형 데이터를 가리지 않습니다. 텍스트와 이미지 분류 문제에 LIME을 이용하는 예시를 통해 LIME이 어떤 알고리즘인지 알아보겠습니다.
먼저, 텍스트 예시입니다. 20 newsgroups 데이터셋은 텍스트 분류 문제에서 유명한 데이터셋입니다. 여기서는 ‘기독교’ 카테고리와 ‘무신론’ 카테고리를 분류하는 모델을 살펴봅니다. 이 두 카테고리는 서로 많은 단어들을 공유하기 때문에 분류하기 어려운 문제로 알려져 있습니다.
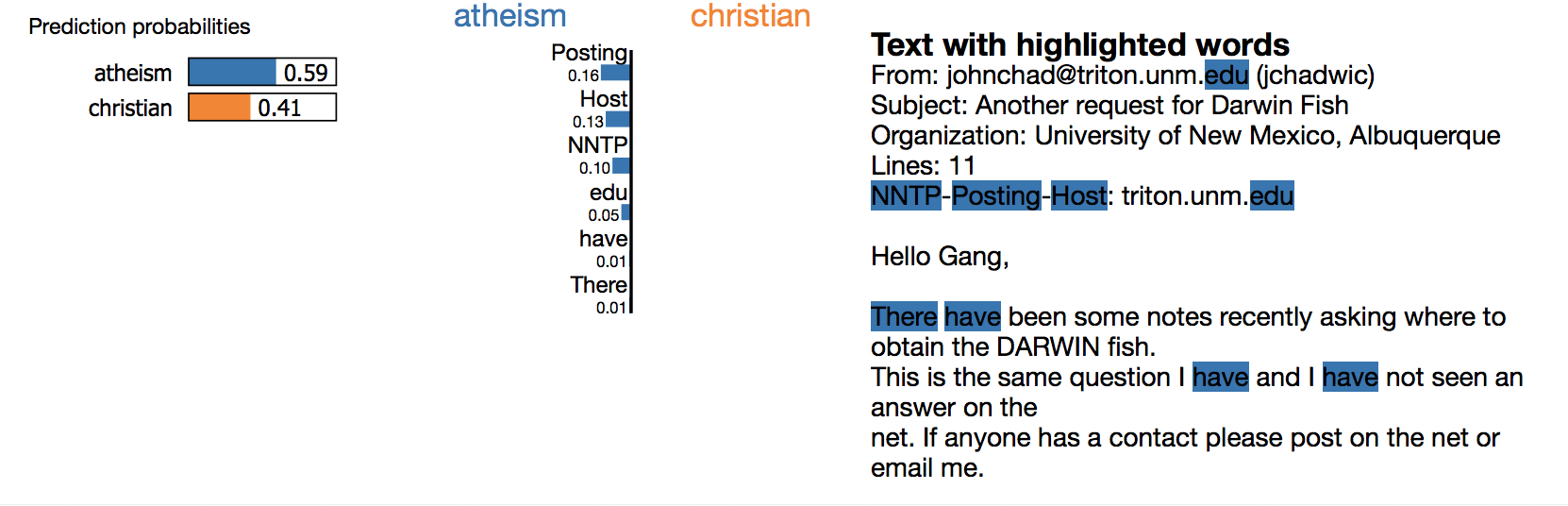
랜덤 포레스트를 의사 결정 나무 500개로 돌리면 92.4%의 평가용 데이터셋 정확도를 얻습니다. 굉장히 높은 수치죠. 만약 정확도가 유일한 신뢰의 지표였다면 분명 이 분류기를 믿었을 겁니다. 하지만, 무작위로 뽑은 데이터에 대한 LIME의 설명을 들여다보면 그 결과는 사뭇 다릅니다.

이것은 모델이 예측은 정확하게 했지만 그 이유는 틀린 경우입니다. 이메일 상단에 있는 ‘posting’이란 단어는 학습 데이터셋에서는 21.6%의 데이터에서 나타나지만 ‘기독교’ 카테고리에서는 두번밖에 나타나지 않습니다. 테스트셋에서도 마찬가지로 데이터 중 20%의 경우에 ‘posting’이 나오지만 ‘기독교’에는 두번밖에 나오지 않습니다. 하지만 실제 현실에서 이런 패턴이 나타날 것이라고 예상하기는 어렵습니다. 이처럼 모델이 대체 뭘 하는지 이해하고 있다면 모델이 얼마나 일반화 가능한지 인사이트를 얻기가 훨씬 쉽습니다.
두번째 예로, 구글의 inception 네트워크의 이미지 분류 결과를 설명해봅시다. 이 경우에는, 아래 그림에서 볼 수 있듯이 분류기는 주어진 이미지가 개구리일 확률이 가장 높다고 예측했습니다. 그 다음으로는 당구대랑 풍선을 좀 더 낮은 확률로 예측했네요.

LIME은 inception 모델이 주어진 이미지를 개구리라고 예측한 데에는 개구리의 얼굴이 가장 중요한 역할을 했다고 설명합니다. 그런데 당구대와 풍선은 왜 나온 것일까요? 개구리의 손과 눈은 당구공을 닮았습니다. 초록색 배경에 당구공 같이 생긴 것들이 있으니 모델이 당구대라고 생각한 것입니다. 개구리가 들고 있는 하트는 빨간색 풍선을 닮았습니다. 이것이 모델이 풍선이라고 예측한 이유입니다. 이렇듯 LIME을 통해 왜 모델이 이런 예측들을 했는지 이해할 수 있습니다.
어떻게 사용하나요?#
LIME은 파이썬 패키지로 공개되어 있습니다. 이제 LIME을 설치하고 사용하는 방법을 알아보겠습니다.
설치하기#
pip으로 쉽게 설치할 수 있습니다.
pip install lime
# for python3
pip3 install lime
예측 함수 모양 맞춰주기#
LIME에 예측 모델을 넣어주기 위해서 예측 모델을 함수 형태로 만들어주어야 합니다. 예측 모델을 scikit-learn로 만들었다면 모델의 predict_proba 함수를 쓰는 것으로 충분합니다. 만약 예측 모델이 TensorFlow 모델이라면 다음과 같이 함수로 만들어줄 수 있습니다. 이 함수의 입력은 원본 데이터이고 출력은 각 카테고리의 확률입니다.
def predict_fn(images):
return session.run(probabilities, feed_dict={processed_images: images})
Explainer 만들기#
데이터의 형식에 따라 만들어줘야 하는 Explainer가 다릅니다. 각 경우를 나눠서 설명드리겠습니다.
이미지의 경우
다음과 같은 이미지에 대한 이미지 분류 모델의 예측값을 설명해봅시다.

# 예측 결과
286 Egyptian cat 0.000892741
242 EntleBucher 0.0163564
239 Greater Swiss Mountain dog 0.0171362
241 Appenzeller 0.0393639
240 Bernese mountain dog 0.829222
먼저, lime 패키지에서 이미지 모듈을 불러옵니다.
from lime.lime_image import LimeImageExplainer
이미지 모듈에서 Explainer를 생성합니다.
explainer = LimeImageExplainer()
특정 이미지에 대한 설명을 생성합니다.
# image : 설명하고자 하는 이미지입니다.
# predict_fn : 위에서 만든 예측 모델 함수입니다.
# hide_color=0 : superpixel을 회색으로 가리겠다는 뜻입니다. 이 인자가 없을 경우 픽셀들 색깔의 평균으로 가려집니다.
# 아래 코드를 실행시킬 때 시간이 다소 걸릴 수 있습니다.
explanation = explainer.explain_instance(image, predict_fn, hide_color=0, top_labels=5, num_samples=1000)
이제 만들어진 설명을 이미지로 나타내봅시다.
from skimage.segmentation import mark_boundaries
temp, mask = explanation.get_image_and_mask(240, positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))

이미지의 나머지 부분도 같이 보고 싶다면 다음과 같이 할 수 있습니다.
temp, mask = explanation.get_image_and_mask(240, positive_only=True, num_features=5, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))

어떤 부분이 개로 예측할 확률을 높이는 부분이었고 어떤 부분이 확률을 낮추는 부분이었는지 보기 위해서는 다음 코드를 씁니다.
temp, mask = explanation.get_image_and_mask(240, positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))
설명을 위해서 코드의 많은 부분을 생략했습니다. Tensorflow에서 slim의 inception v3 모델을 LIME으로 설명하는 전체 코드는 여기에서 볼 수 있습니다.
텍스트의 경우
lime 패키지에서 텍스트 모듈을 불러옵니다.
from lime.lime_text import LimeTextExplainer
텍스트 모듈에서 Explainer를 생성합니다.
# class_names : 각 카테고리들의 이름을 줄 수 있습니다. (없는 경우 0, 1 같은 index로 보여집니다.)
explainer = LimeTextExplainer(class_names=class_names)
특정 텍스트에 대한 설명을 생성합니다.
# text : 설명하고자 하는 텍스트입니다.
# predict_fn : 예측 모델 함수입니다.
explanation = explainer.explain_instance(text, predict_fn, num_features=6)
이제 만들어진 설명을 확인해봅시다. LIME은 시각적으로 한 눈에 들어오도록 설명을 html로 생성하는 기능도 갖고 있습니다. 그리고 이 설명을 Jupyter Notebook에서 보기도 쉽게 되어 있습니다.
explanation.show_in_notebook(text=True)
전체 코드는 여기에서 볼 수 있습니다.
이밖에도 수치형 테이블 데이터에 대해서, 또는 회귀 문제에 대해서도 LIME을 적용할 수 있습니다.
어떻게 작동하나요?#
LIME의 핵심 아이디어는 이것입니다.
입력값을 조금 바꿨을 때 모델의 예측값이 크게 바뀌면, 그 변수는 중요한 변수이다.
이미지 분류 문제에 LIME을 적용하는 예시를 들어보겠습니다. 먼저 그림을 superpixel이라고 불리는 해석 가능한 요소로 쪼개는 전처리 과정을 거칩니다.

그리고 나서 변수에 약간의 변화(perturbation)를 줍니다. 이미지의 경우에는 superpixel 몇개를 찝어서 회색으로 가립니다. 그리고 모델에 넣고 예측값을 구합니다. 만약 예측값이 많이 변하면 가렸던 부분이 중요했다는 것을 알 수 있겠죠. 반대로 예측값이 많이 달라지지 않았으면 가렸던 부분이 별로 중요하지 않았나보다, 라고 알게 되겠죠.
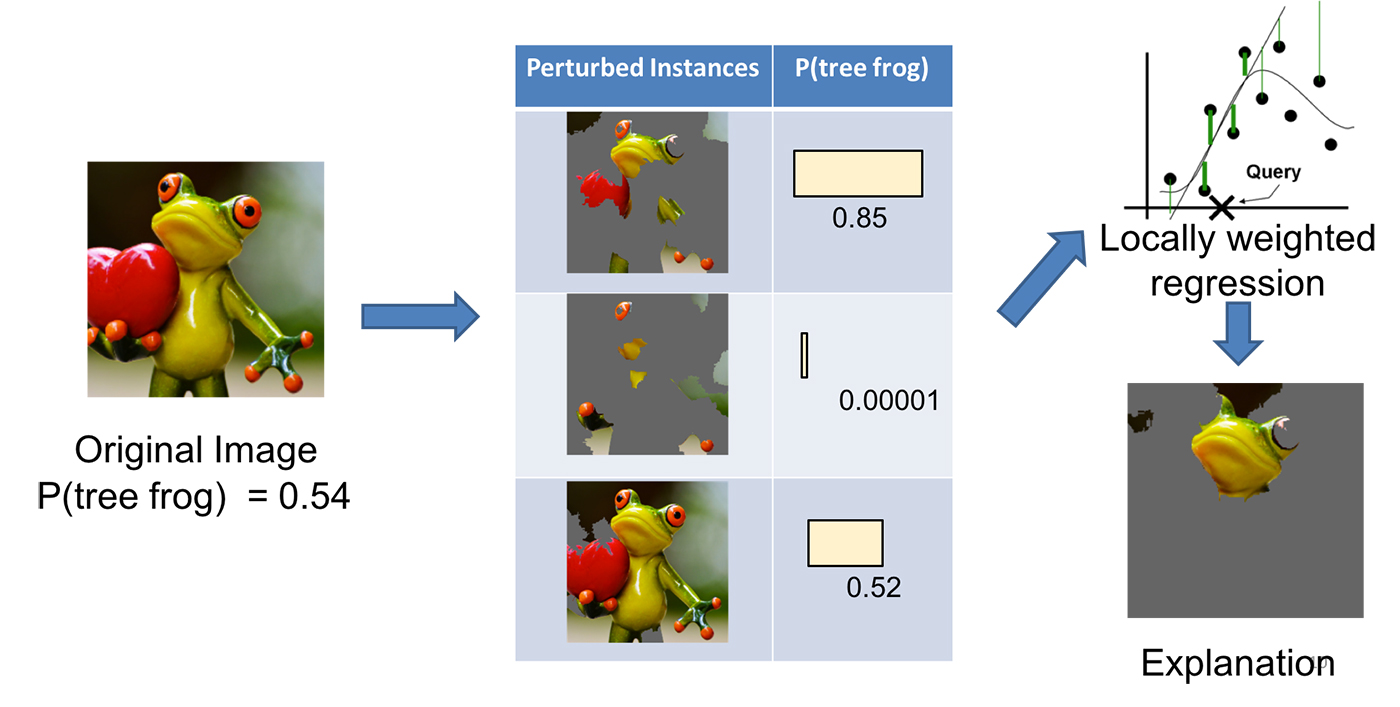
위 예시에서 원본 사진은 0.54 확률로 개구리로 예측됩니다. 이 사진을 첫번째 변형(perturbed instance)처럼 가렸더니 개구리일 확률이 0.85로 높아졌습니다. 사진에서 남은 부분이 개구리라고 예측하는 데 중요한 요소라는 것을 알 수 있죠. 두번째 변형처럼 가렸더니 개구리일 확률이 0.00001로 매우 낮아졌습니다. 그러면 방금 가린 부분이 개구리라고 판단하는 데 중요한 요소였다는 것을 알 수 있겠죠. 세번째 변형처럼 가리면 개구리일 확률이 별로 변하지 않습니다. 이때 가린 부분은 개구리라고 판단하는 데 별로 중요하지 않았다는 것을 알 수 있죠. 이렇게 여러번의 과정을 거친 뒤 결국 어떤 superpixel이 개구리라고 판단하는 데 가장 중요했는지 찾는 것이 LIME의 핵심입니다.
이 방법은 두가지 점에서 장점이 있습니다. 첫째, 이 방법은 어떤 모델이든 상관 없이(model-agnostic) 적용할 수 있는 방법입니다. 둘째, 이 방법은 해석가능성의 측면에서 굉장한 이점을 갖고 있는데요, 입력은 모델 내부의 변수보다 인간이 이해하기 훨씬 쉽기 때문입니다. 예를 들어 모델이 내부적으로는 word embedding 같이 복잡한 속성을 쓰고 있더라도, 모델의 입력인 단어는 인간이 이해할 수 있는 방식으로 살짝 바꿔보기가 훨씬 쉽죠.
LIME은 한번에 하나의 데이터에 대해서만 모델의 예측 결과를 설명합니다. 그리고 그 데이터를 예측하는 데 중요했던 변수만을 뽑아줍니다. 예를 들어, 어떤 환자가 독감이 걸렸다고 진단할 때 중요했던 증상들은 아마도 위염을 가진 환자를 진단할 때 중요하지 않을 수도 있겠죠.
수학적으로 LIME이 블랙 박스 모델을 설명하는 방법은 모델을 해석 가능한 간단한 선형 모델로 근사하는 것입니다. 복잡한 모델 전체를 근사하는 것은 어렵지만, 우리가 설명하고 싶은 예측 주변에 대해서만 간단한 모델로 근사하는 것은 매우 쉽습니다.
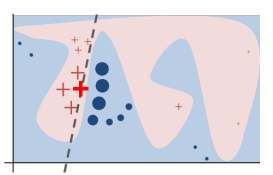
이해를 돕기 위해서 아래 그림처럼 어떤 모델의 변수가 두 개만 있고 데이터를 두 변수를 이용해 파란색과 붉은색 두 클래스로 분류한다고 생각해 봅시다. 모델의 decision boundary(빨간색과 파란색이 나뉘는 경계)는 매우 복잡합니다. 하지만 아래 그림처럼 우리가 설명하려는 데이터(굵은 빨간 십자가)의 살짝 옆에만 본다면, 그 주변만 근사한 선형 함수를 만들어낼 수 있습니다. 이 선형 함수는 전체적으로 보면 원래 모델과는 전혀 다르지만, 특정 예시 주위에서는 원래 모델과 비슷하게 행동합니다. 이렇게 만든 간단한 선형 함수를 보면 이 예시에서 어떤 변수가 중요한 역할을 하는지 알 수 있죠. 이것이 LIME에 Local이라는 말이 붙는 이유입니다.
좀 더 구체적으로 들어가면 선형 함수로의 근사는 다음과 같은 방법으로 구현됩니다. 먼저 원본 데이터를 살짝 변형시켜서(이미지의 일부를 가리거나 단어를 제거해서) 데이터셋을 만듭니다. 각각의 변형된 데이터를 모델에 넣어서 예측값을 구합니다. 그 다음 이 데이터셋에 간단한 선형 모델을 학습시키는데, 이 때 변형된 데이터와 원본 데이터 간의 유사성만큼 가중치를 줍니다. 이렇게 하면 주로 원본 데이터와 가까운 영역에서 블랙 박스 모델과 비슷하게 행동하는 선형 모델을 만들 수 있습니다. 이 방식으로 LIME은 원본 데이터에 대한 예측의 설명을 만들어냅니다.
마치며#
블랙 박스 모델을 열어 그 속을 들여다볼 수 있다는 것은 큰 이점이죠. 이 점에서 LIME은 머신 러닝을 사용하는 사람들에게 매우 유용한 도구입니다.
저는 LIME을 사용하다가 한글이 깨지는 문제를 발견하고 이를 해결하는 pull request로 LIME의 contributor가 되었습니다. 이처럼 LIME은 빠르게 발전하는 모델이고 지금도 기능 추가와 개선이 꾸준히 일어나는 프로젝트입니다.

지금까지 거의 모든 머신 러닝 프로젝트는 “데이터 수집 -> 전처리 -> 모델링 -> 결론"으로 끝났습니다. 앞으로는 여기에서 끝나지 않고 LIME과 같은 도구를 이용해 모델을 설명하는 단계가 필수적이 될 것이라고 생각합니다.
LIME을 요약하는 3분짜리 짧은 동영상으로 이 글을 마치겠습니다.

참고 자료#
이 글은 다음 자료들을 바탕으로 쓰여졌습니다.