AWS Lambda로 PyTorch 모델 서빙하기
AWS Lambda로 PyTorch 모델 서빙하기#
AWS Lambda는 서버 관리의 부담을 없애주는 서버 리스 컴퓨팅(Serverless computing) 서비스입니다. Lambda를 한마디로 설명하면 이벤트가 발생했을 때만 서버가 떠서 코드를 실행하는 이벤트 기반 클라우드 플랫폼입니다. Lambda는 코드가 실행된 시간에 대해서만 비용을 내는 효율성과, 이벤트가 갑자기 많이 발생해도 병렬처리가 가능한 확장성 덕분에 각광받고 있습니다.
이 글에서는 Lambda 위에 PyTorch 모델을 업로드하여 API로 서비스하는 방법을 공유하겠습니다. 이 글은 step-by-step으로 구성되어 있습니다. 배포 준비를 위해 Docker를 설치하고 PyTorch 라이브러리와 모델을 압축파일로 만들고 Lambda 위에 올린 뒤 API를 배포하는 것까지 차근차근 따라가 보겠습니다.
이 글에서 쓰이는 모든 코드는 github에 모아놓았습니다 : github
샘플 모델 만들기#
이 글에서 예제로 사용할 모델은 PyTorch Tutorial에서 제공하는 Generating Names with a Character-Level RNN 모델입니다. 텍스트로 인풋을 받고 텍스트로 아웃풋을 내기 때문에 API 설계가 간단해지는 장점이 있어 선택했습니다. 튜토리얼의 코드를 그대로 쓰되, 마지막에 학습된 모델을 저장하는 코드만 추가해서 사용하겠습니다. 아래는 맨 아래에 추가되는 코드입니다.
# char_rnn_generation_tutorial.py
# 튜토리얼 코드 생략
# Save the model
torch.save(rnn.state_dict(), 'model.pth')
import pickle
to_pickle = {
'all_categories': all_categories,
'n_categories': n_categories,
'all_letters': all_letters,
'n_letters': n_letters
}
with open('params.pkl', 'wb') as file:
pickle.dump(to_pickle, file)
PyTorch 모델을 저장할 때는 모델 전체가 아니라 모델의 state dict만 저장합니다. 이것은 모델을 다른 환경 위에서도 문제 없이 load하기 위해서입니다. PyTorch 모델을 저장하고 불러오는 방법은 공식 문서인 Recommended approach for saving a model을 따랐습니다.
코드를 실행하면 저장된 모델 파일인 model.pth과 전처리를 위한 파라미터 파일인 params.pkl을 얻을 수 있습니다.
Docker 설치하기#
Lambda에서 코드를 실행하는 환경과 동일한 환경을 로컬에 쉽게 구성하기 위해서는 Docker가 필요합니다. Lambda에 올린 코드를 디버깅할 때도 Docker에서 코드를 테스트해보는 것은 유용하죠.
Docker가 이미 설치되어 있으신 분은 이 부분을 생략하고 바로 다음으로 넘어가셔도 됩니다.
MacOS & Windows#
Docker Community Edition 다운로드 페이지에서 원하는 환경의 설치 파일을 다운로드받으면 GUI 방식으로 쉽게 설치할 수 있습니다.
Ubuntu#
간편하게 만들어진 스크립트를 실행함으로써 Docker를 설치할 수 있습니다.
이미 Docker가 설치되어 있다면 아래 스크립트를 실행하지 마세요. 아래 스크립트에 대한 자세한 설명은 설치 페이지에서 읽을 수 있습니다.
$ curl -fsSL get.docker.com -o get-docker.sh
$ sudo sh get-docker.sh
그 후 Docker를 사용할 유저에게 권한을 주기 위해 유저를 Docker 그룹에 추가합니다.
sudo usermod -aG docker <your-user>
참고로 제가 실험해보았을 때는, 이 글의 뒤에 나오는대로 PyTorch를 설치하고 불필요한 파일을 삭제했을 때 Linux (Ubuntu 14.04)에서는 AWS Lambda에 올릴 수 있는 크기가 나왔지만 MacOS (Sierra)에서는 그보다 큰 용량이 나왔습니다. 여러가지 환경에 따라 결과는 달라질 수 있으니 직접 실험해보는 것을 권장합니다.
Amazon Linux Docker 이미지 다운받기#
Lambda에서 코드를 실행할 때 사용하는 환경은 Amazon Linux입니다. 따라서 Lambda의 배포 환경과 동일한 환경을 구축하기 위해서는 Docker를 이용해 Amazon Linux 이미지를 다운받아야 합니다.
$ docker pull amazonlinux:latest
다운로드가 끝나면 다음 명령어로 설치된 이미지를 확인할 수 있습니다.
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
amazonlinux latest 6133b2c7d7c2 2 hours ago 165MB
배포 패키지 압축 파일 만들기#
이제 Lambda에 업로드할 압축 파일(.zip)을 만들어야 합니다. 이를 위해서 Amazon Linux 환경 위에 필요한 패키지들을 모두 설치하고 설치된 파일을 압축하는 과정이 필요합니다.
다음 코드는 그 과정을 모두 담고 있습니다. 코드에 대한 설명은 아래에 있습니다.
# build_pack_script.sh
dev_install () {
yum -y update
yum -y upgrade
yum -y groupinstall "Development Tools"
yum install -y findutils zip
yum install -y python36-devel python36-virtualenv
}
make_virtualenv () {
cd /home
rm -rf env
python3 -m virtualenv env --python=python3
source env/bin/activate
}
install_pytorch () {
pip install http://download.pytorch.org/whl/cpu/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl
pip install torchvision
}
install_packages () {
pip install -r /host/requirements.txt
}
gather_pack () {
cd /home
rm -rf lambdapack
mkdir lambdapack
cd lambdapack
# Copy python pakages from virtual environment
cp -R /home/env/lib/python3.6/site-packages/* .
cp -R /home/env/lib64/python3.6/site-packages/* .
echo "Original size $(du -sh /home/lambdapack | cut -f1)"
# Clean pakages
find . -type d -name "tests" -exec rm -rf {} +
find -name "*.so" | xargs strip
find -name "*.so.*" | xargs strip
rm -r pip
rm -r pip-*
rm -r wheel
rm -r wheel-*
rm easy_install.py
find . -name \*.pyc -delete
echo "Stripped size $(du -sh /home/lambdapack | cut -f1)"
# Compress
zip -FS -r1 /host/pack.zip * > /dev/null
echo "Compressed size $(du -sh /host/pack.zip | cut -f1)"
}
add_pack () {
cd /host
zip -9 -q -r pack.zip lambda_function.py
zip -9 -q -r pack.zip model.py
}
main () {
dev_install
make_virtualenv
install_pytorch
install_packages
gather_pack
add_pack
}
main
위의 코드를 다음과 같이 실행할 수 있습니다.
$ docker run -d -t --name lambdapack -v $(pwd):/host amazonlinux:latest
$ docker exec -i -t lambdapack bash /host/build_pack_script.sh
...
Successfully installed numpy-1.14.0
Successfully installed pyyaml-3.12 torch-0.3.0.post4
Successfully installed pillow-5.0.0 six-1.11.0 torchvision-0.2.0
...
Original size 310M
Stripped size 249M
Compressed size 71M
그 후 이 코드를 실행한 디렉토리에 pack.zip이라는 압축파일이 생성된 것을 볼 수 있습니다. 이 압축파일 안에 우리가 실행할 코드와 라이브러리가 모두 들어 있습니다.
이 압축파일을 Lambda에 올리고 API로 만드는 방법으로 넘어가기 전에, 위의 코드에서 중요한 부분을 몇가지 설명드리겠습니다.
PyTorch 설치하기#
PyTorch를 CPU 버전으로 설치합니다. 참고로 CUDA 버전은 용량이 800MB에 달해서 Lambda에 올릴 수 있는 코드와 라이브러리 크기 제한인 250MB를 훨씬 뛰어넘습니다. Lambda에서는 CPU로 코드를 실행하기 때문에 CUDA 버전은 필요 없습니다.
참고로 Lambda의 코드와 라이브러리 크기 제한은 압축 해제 시를 기준으로 합니다.
lambda_function.py#
build_pack_script.sh 코드 중 add_pack에서 lambda_function.py이란 파일을 압축 파일에 추가하는 부분이 있습니다. Lambda가 실제로 실행하는 코드는 바로 이 lambda_function.py 파일 안의 lambda_handler라는 함수입니다. 이 파일 역시 다른 라이브러리들과 함께 압축 파일 안에 포함되어 Lambda에 업로드되어야 합니다. 실행하는 파일과 함수의 이름을 Lambda 설정에서 변경할 수는 있지만 여기서는 디폴트 대로 파일과 함수 이름을 지었습니다.
lambda_function.py의 내용을 하나씩 살펴보겠습니다.
import boto3
import os
import pickle
import numpy as np
import torch
from model import RNN
필요한 패키지를 불러오는 부분입니다. 모든 패키지는 build_pack.sh을 실행할 때 pack.zip 안에 함께 들어가야 합니다. 단, boto3는 Lambda에 이미 설치되어 있으니 따로 설치할 필요는 없습니다.
ACCESS_KEY = os.environ.get('ACCESS_KEY')
SECRET_KEY = os.environ.get('SECRET_KEY')
BUCKET_NAME = os.environ.get('BUCKET_NAME')
max_length = os.environ.get('max_length') # 20
Lambda에서는 설정으로 환경 변수를 지정할 수 있습니다. 이 환경 변수는 코드 내에서 os.environ.get 함수를 통해 가져올 수 있습니다. 참고로 모든 환경변수는 문자열 타입입니다.
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
)
Lambda 내에서 S3에 접근하기 위해 위와 같이 s3 client를 생성합니다.
# Load preprocessing parameters
if not os.path.isfile('/tmp/params.pkl'):
s3_client.download_file(BUCKET_NAME, 'params.pkl', '/tmp/params.pkl')
with open('/tmp/params.pkl', 'rb') as pkl:
params = pickle.load(pkl)
all_categories = params['all_categories']
n_categories = params['n_categories']
all_letters = params['all_letters']
n_letters = params['n_letters']
# Check if models are available
# Download model from S3 if model is not already present
if not os.path.isfile('/tmp/model.pth'):
s3_client.download_file(BUCKET_NAME, 'model.pth', '/tmp/model.pth')
rnn = RNN(n_letters, 128, n_letters, n_categories=n_categories)
rnn.load_state_dict(torch.load("/tmp/model.pth"))
샘플 모델을 학습한 뒤 저장한 model.pth와 params.pkl은 AWS S3에 올린 뒤 Lambda가 실행될 때 /tmp/ 디렉토리 안으로 다운로드합니다. 이 예제에서는 모델의 크기가 매우 작기 때문에 이럴 필요는 없지만, 일반적인 경우에도 적용 가능하도록 예제를 만들었습니다. 이렇게 모델 파라미터를 S3에서 다운받는 것의 또 하나의 장점은 모델을 새로 학습시켜서 파라미터가 바뀌었을 때, 처음부터 다시 패키지 압축을 하지 않고 S3에 올려져 있는 모델 파라미터 파일을 교체하는 것만으로도 배포된 모델을 업데이트할 수 있다는 점입니다. 참고로 /tmp/ 디렉토리 안에는 500MB까지 저장이 가능합니다.
모델 파일을 S3에서 가져오면 lambda 함수가 실행될 때마다 네트워크 비용을 감수해야 하는 단점은 있습니다. 그러나 람다가 병렬 처리로 동작하고 S3 위의 파일은 읽기에 lock이 걸리지 않아 여러명이 동시에 읽을 수 있습니다. S3와 lambda 함수가 같은 region에 있다면 속도 저하를 거의 느낄 수 없는 수준입니다.
# samples 함수 실행을 위해 튜토리얼에서 그대로 가져온 기타 함수들은 생략
# Get multiple samples from one category and multiple starting letters
def samples(category, start_letters='ABC'):
for start_letter in start_letters:
yield sample(category, start_letter)
def lambda_handler(event, context):
# Create dummy input for model
if LEAVE_LOG: print('event:', event)
output_names = list(samples('Russian', 'RUS'))
# return results formatted for AWS API Gateway
return {"statusCode": 200, \
"headers": {"Content-Type": "application/json"}, \
"body": json.dumps(output_names)}
AWS Lambda가 실제로 실행하는 것은 lambda_handler입니다. lambda_handler 함수가 실행될 때 event와 context 안에 lambda를 호출한 이벤트의 정보가 담깁니다. event 변수의 구체적인 형태는 이벤트 종류마다 다르지만, 이 예제의 경우 다음과 같은 정보가 event 객체가 담기게 됩니다.
event: {'category': 'Russian', 'start_letters': 'RUS'}
model.py와 requirements.txt#
github에는 위에 설명드린 파일 외에도 몇가지 파일들이 더 있습니다.
model.py는 모델 정의가 그대로 담겨 있는 파일입니다. PyTorch 모델을 불러올 때는 모델 class 정의가 필요하기 때문입니다. 샘플 모델 대신 자신의 모델을 쓰고 싶다면 이 파일을 수정해주어야 합니다.
requirements.txt는 추가적으로 필요한 파이썬 패키지들을 명시하는 곳입니다. Pandas 등 필요한 패키지를 이곳에 적어놓으면 build_pack_script.sh가 실행되어 압축 파일을 만들면서 명시된 패키지가 함께 들어갑니다. 이 때 Stripped size가 250MB를 넘어서는 안된다는 점을 명심해주세요. 참고로 예시에는 로컬에서 테스트를 위해 boto3가 포함되어 있지만, 실제 Lambda에는 boto3가 이미 설치되어 있으므로 생략하는 것이 좋습니다.
AWS Lambda로 배포하기#
압축 파일 및 모델 파일 업로드#
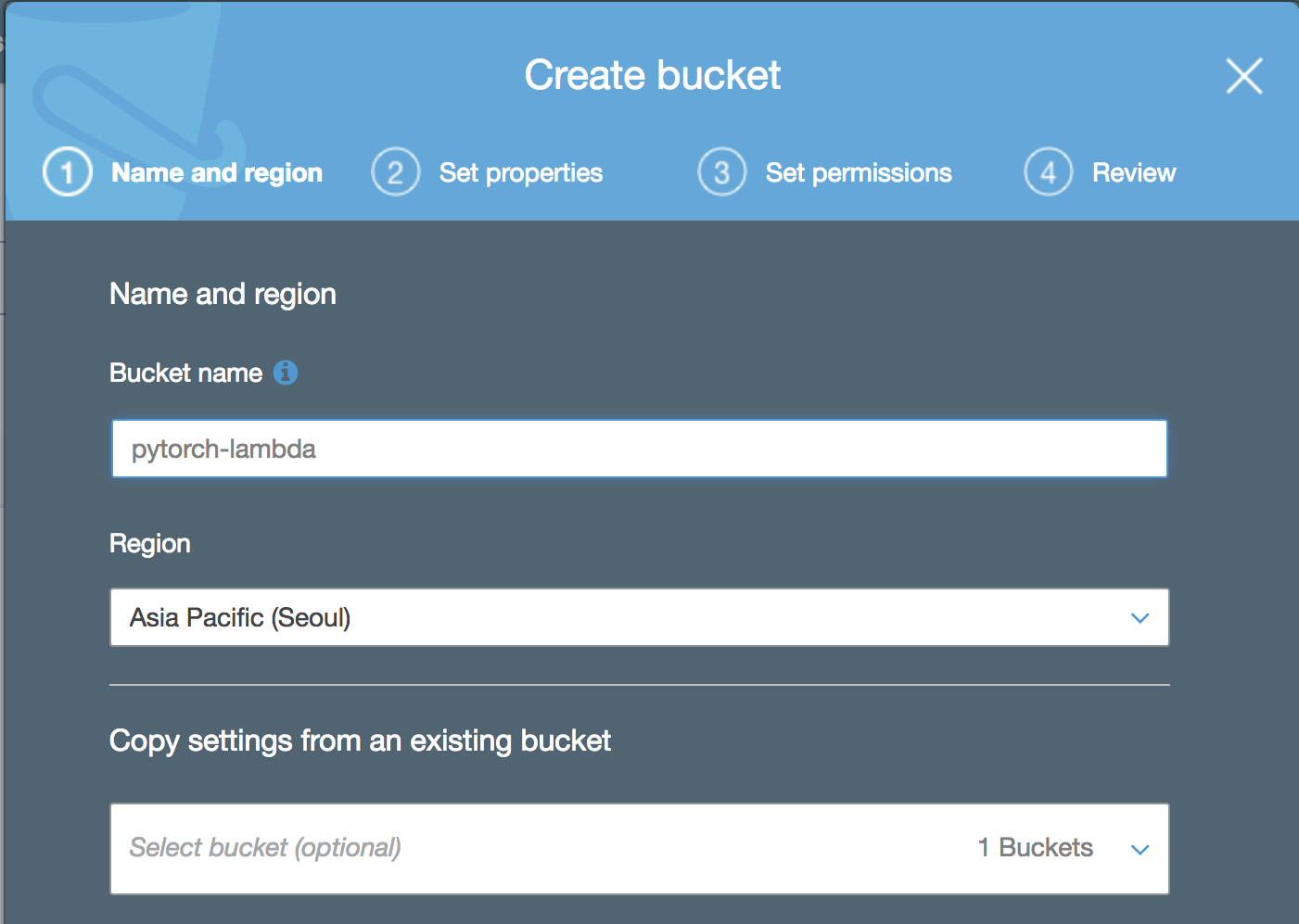
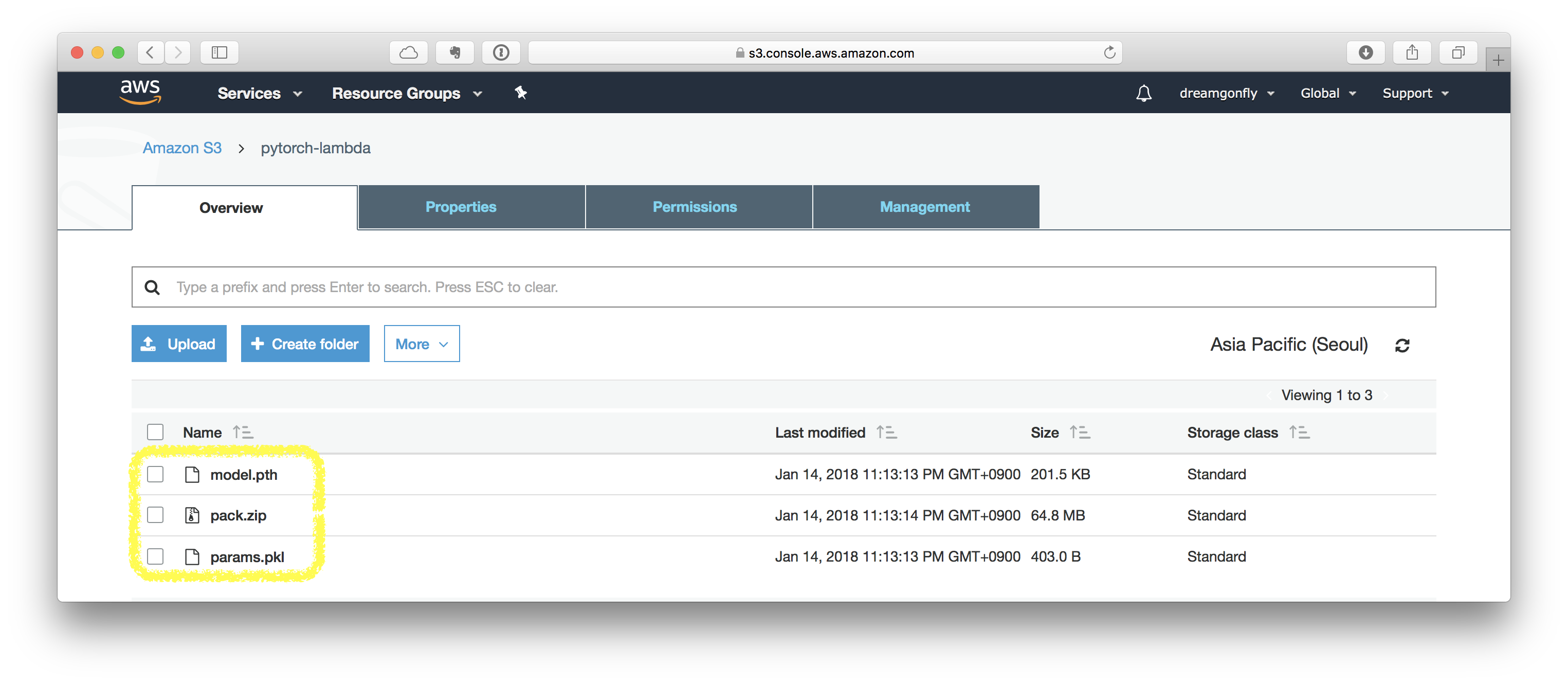
AWS Lambda에 코드를 올리는 방법은 세 가지가 있습니다. 이 중 압축된 파일의 크기가 50MB를 넘는다면 압축 파일을 S3에 업로드한 뒤 Lambda에 압축 파일의 주소를 입력하는 방법을 사용해야 합니다. 이를 위해서 S3에 압축 파일을 업로드합니다. 또한 모델 파라미터와 전처리 파라미터 파일도 같이 S3에 업로드합니다.
이 글에서는 새로운 S3 bucket을 만들고 그곳에 필요한 모든 파일을 업로드하겠습니다. 하지만 실제로는 이미 있는 bucket을 사용해도 되며 모든 파일이 같은 곳에 위치할 필요는 없습니다.
IAM User 만들기#
lambda 함수는 모델과 전처리 파라미터를 S3에서 가져오기 때문에 S3에 접근 권한이 필요합니다. root 권한을 줄 수도 있지만 보안에 취약해진다는 단점이 있습니다. 안전한 권한 관리를 위해서 S3 읽기 권한만 갖고 있는 새 IAM User를 만들어보겠습니다.
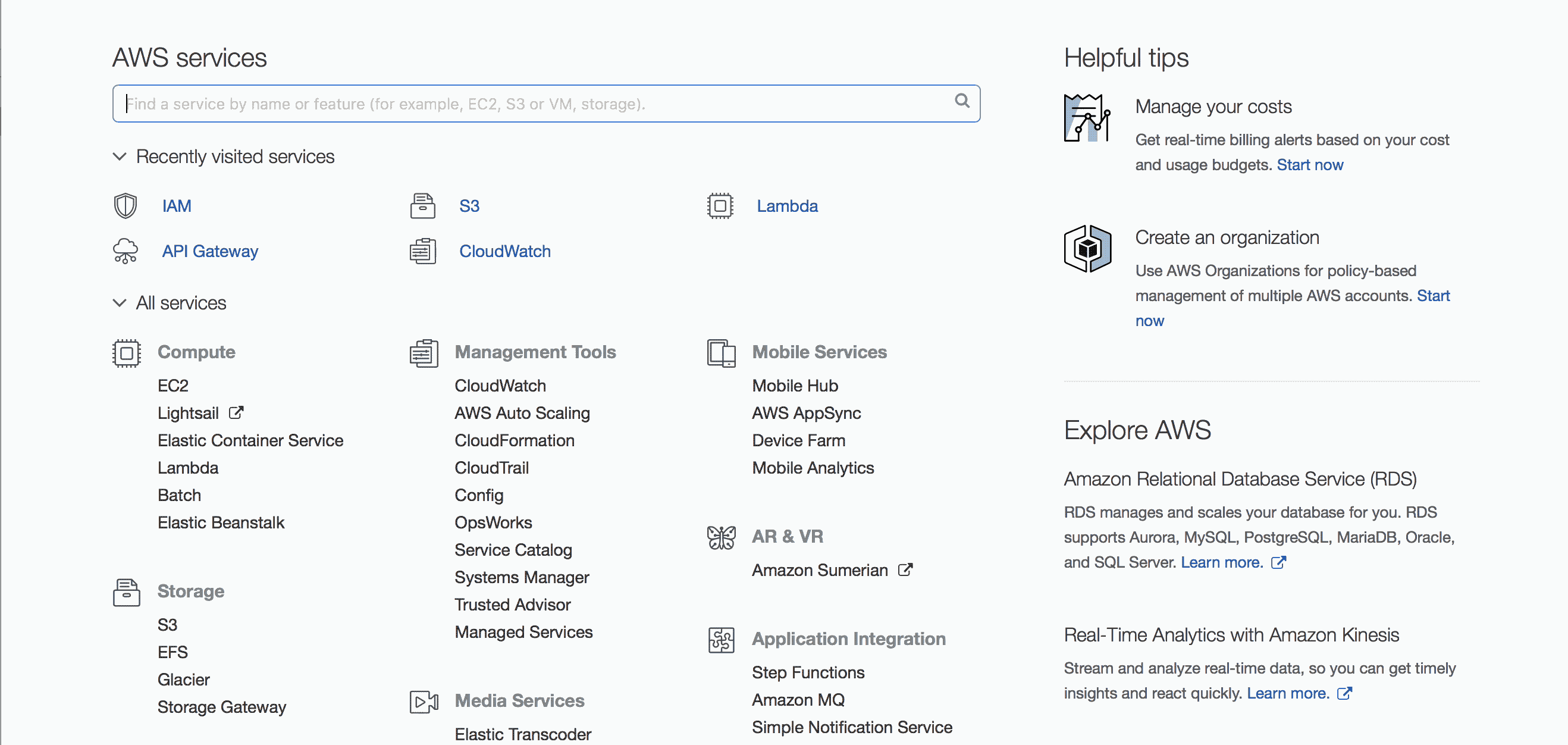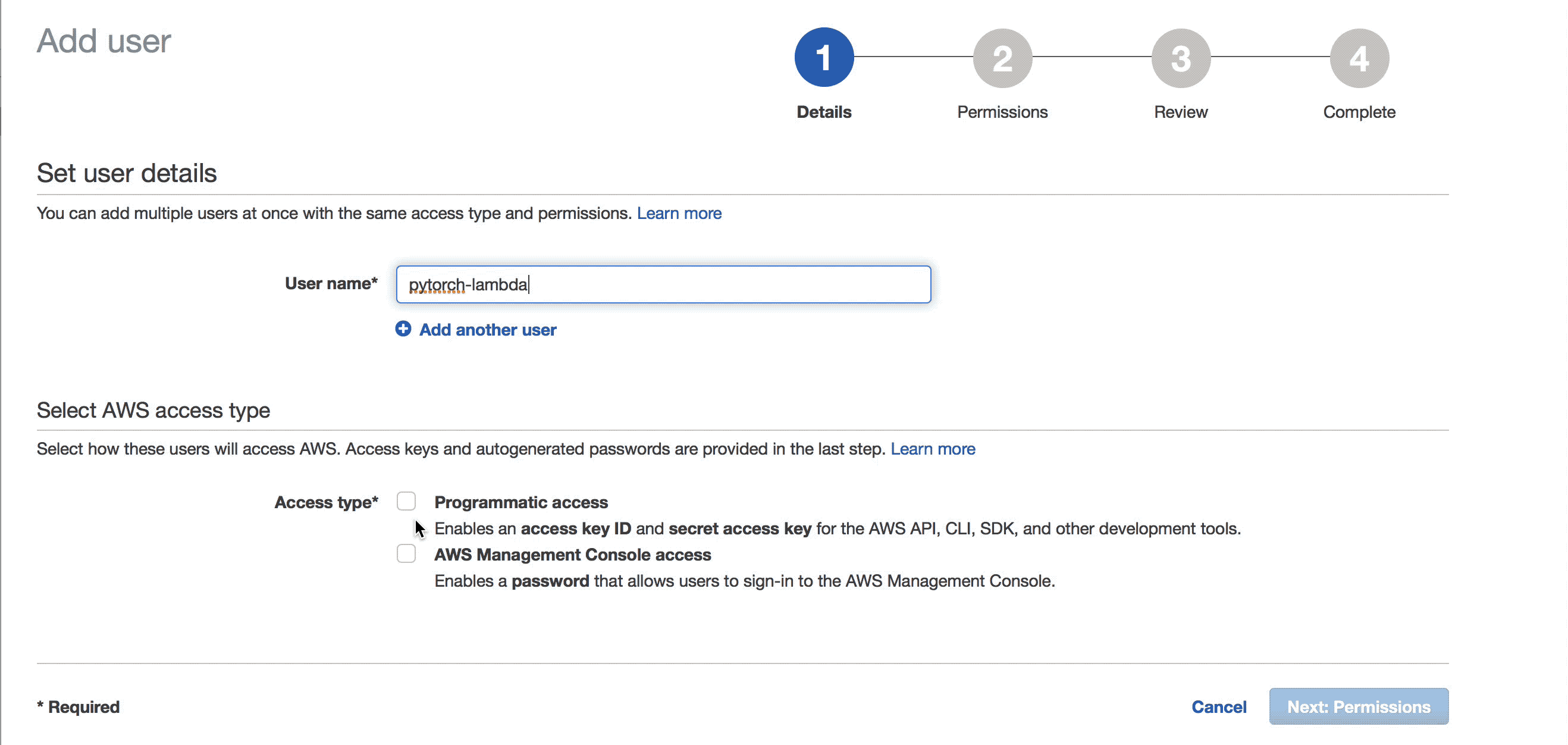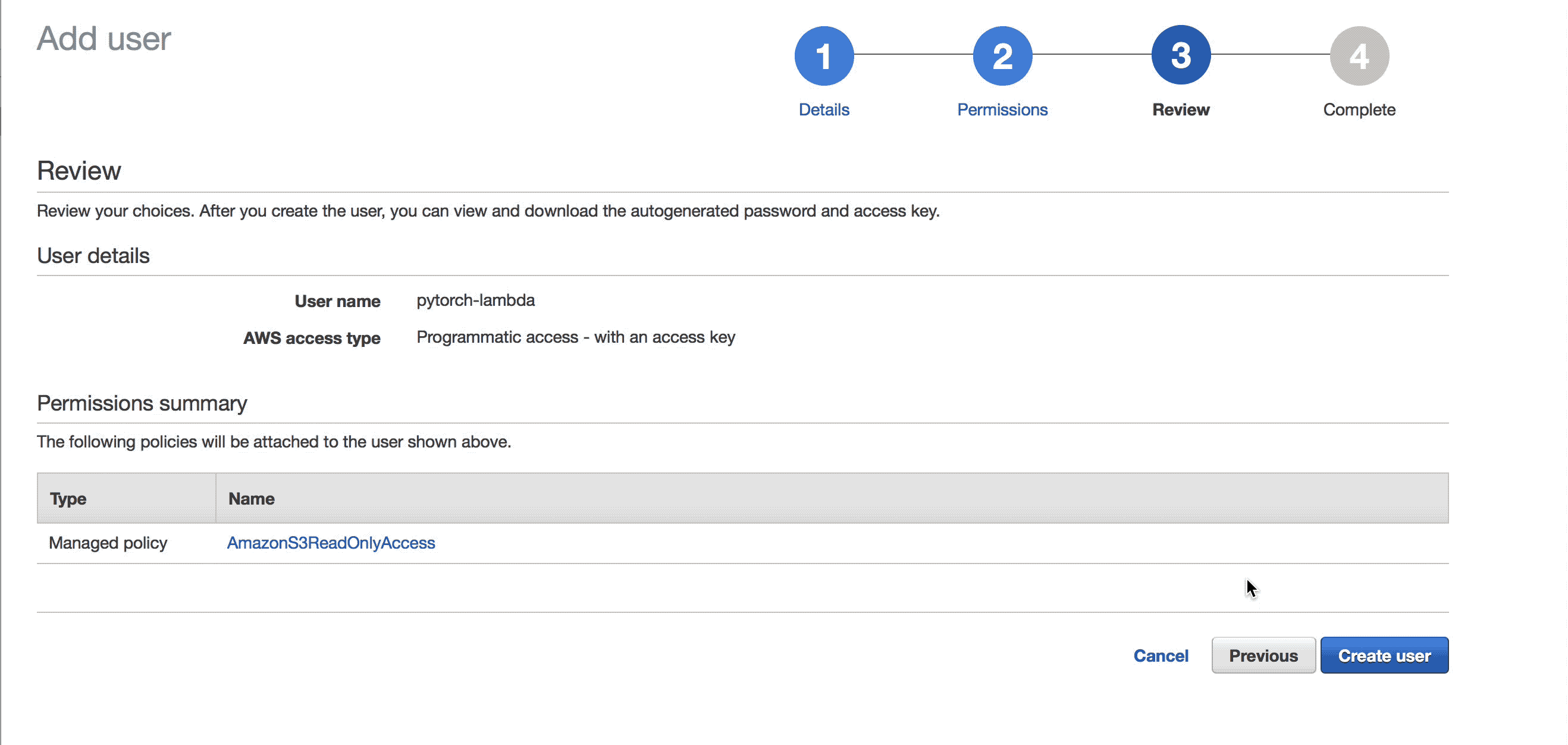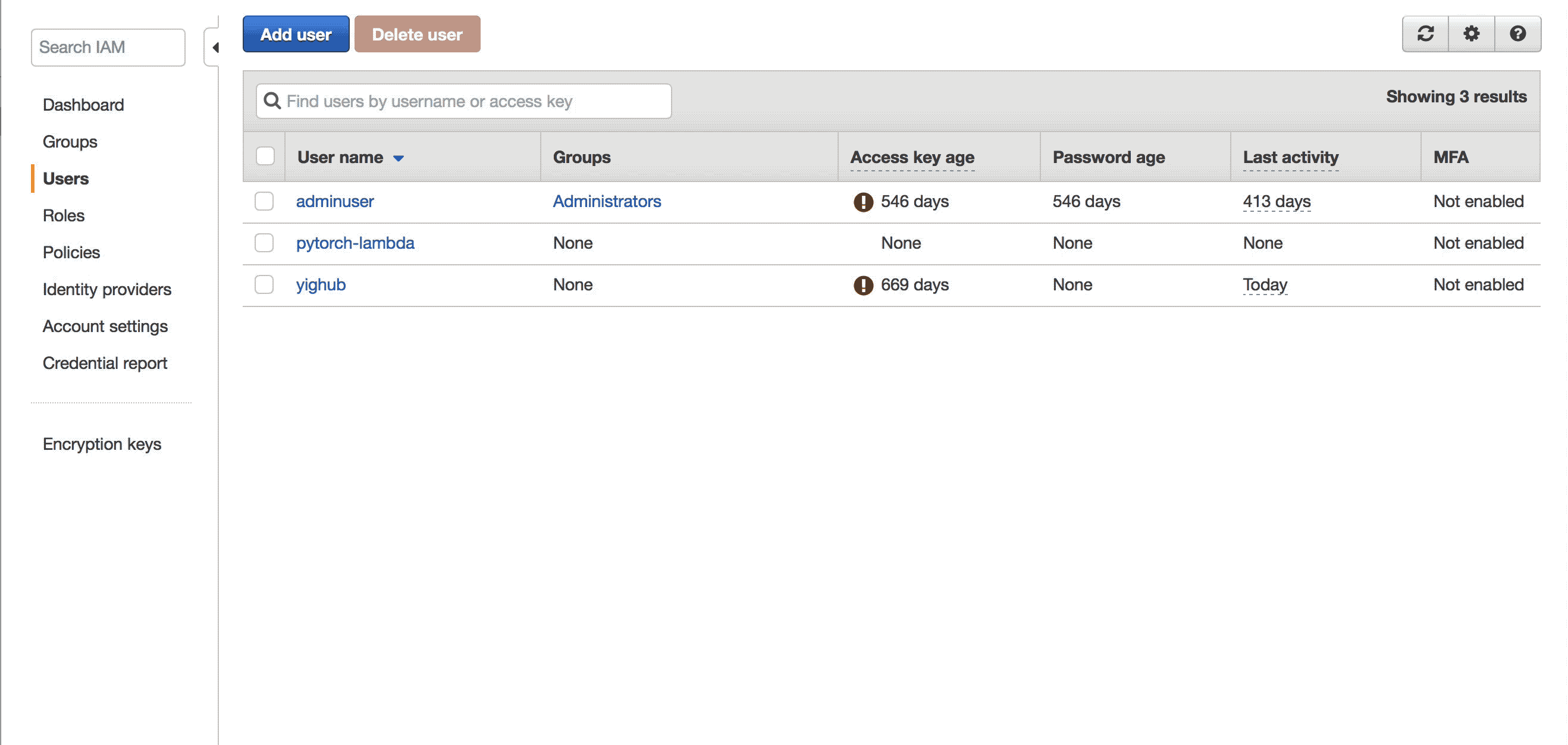
만들어진 유저의 Access key와 Secret access key는 안전한 곳에 잘 저장해놓아야 합니다. 한번 창을 닫으면 Access key와 Secret access key를 다시 볼 수 있는 방법은 없습니다.
lambda 함수 만들기#
이제 새 lambda 함수를 만들어보겠습니다. pytorch-lambda라는 이름의 lambda 함수를 만듭니다. 이 때, 코드 및 라이브러리는 S3에 올려둔 압축 파일의 주소를 입력합니다.
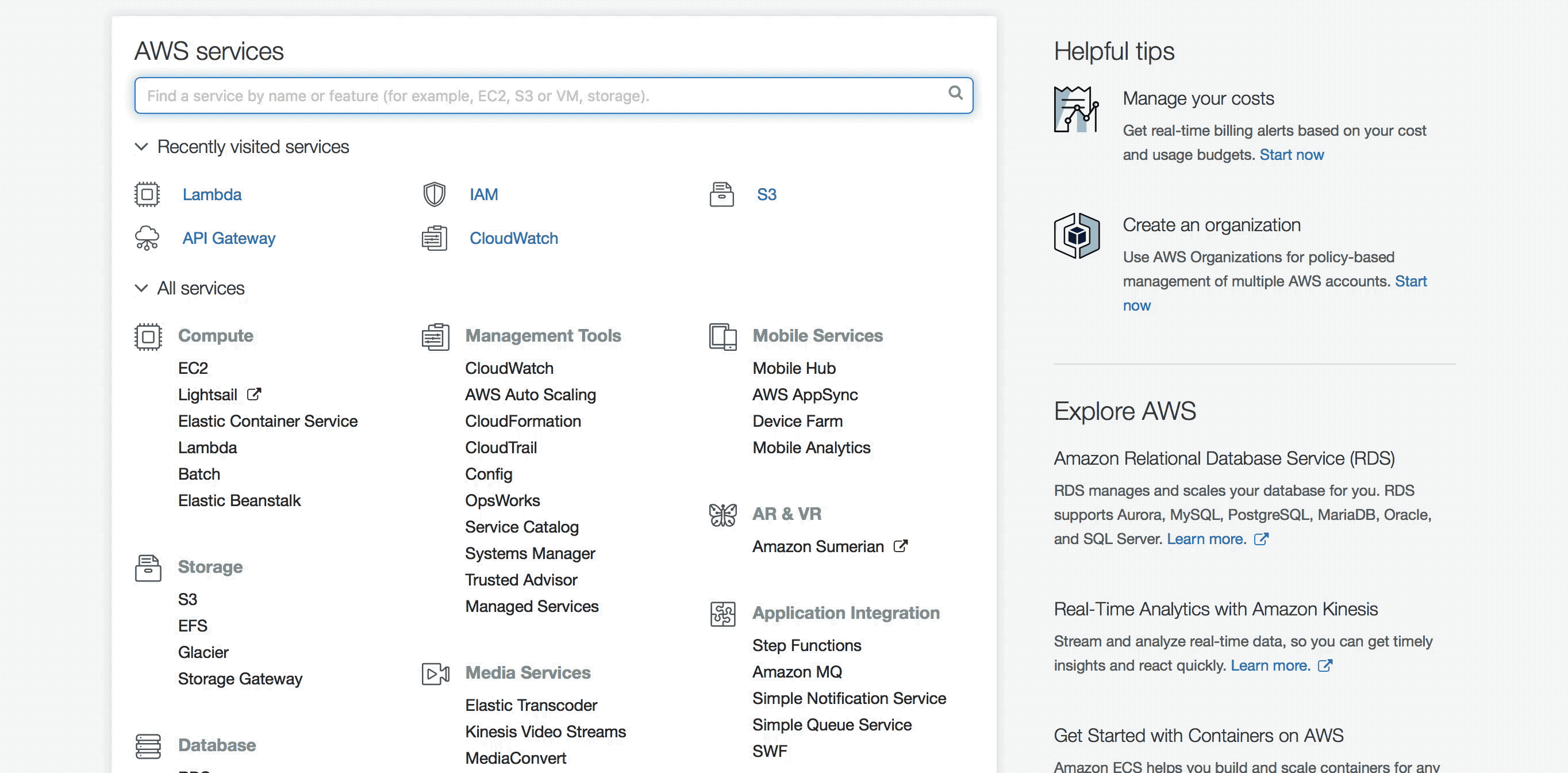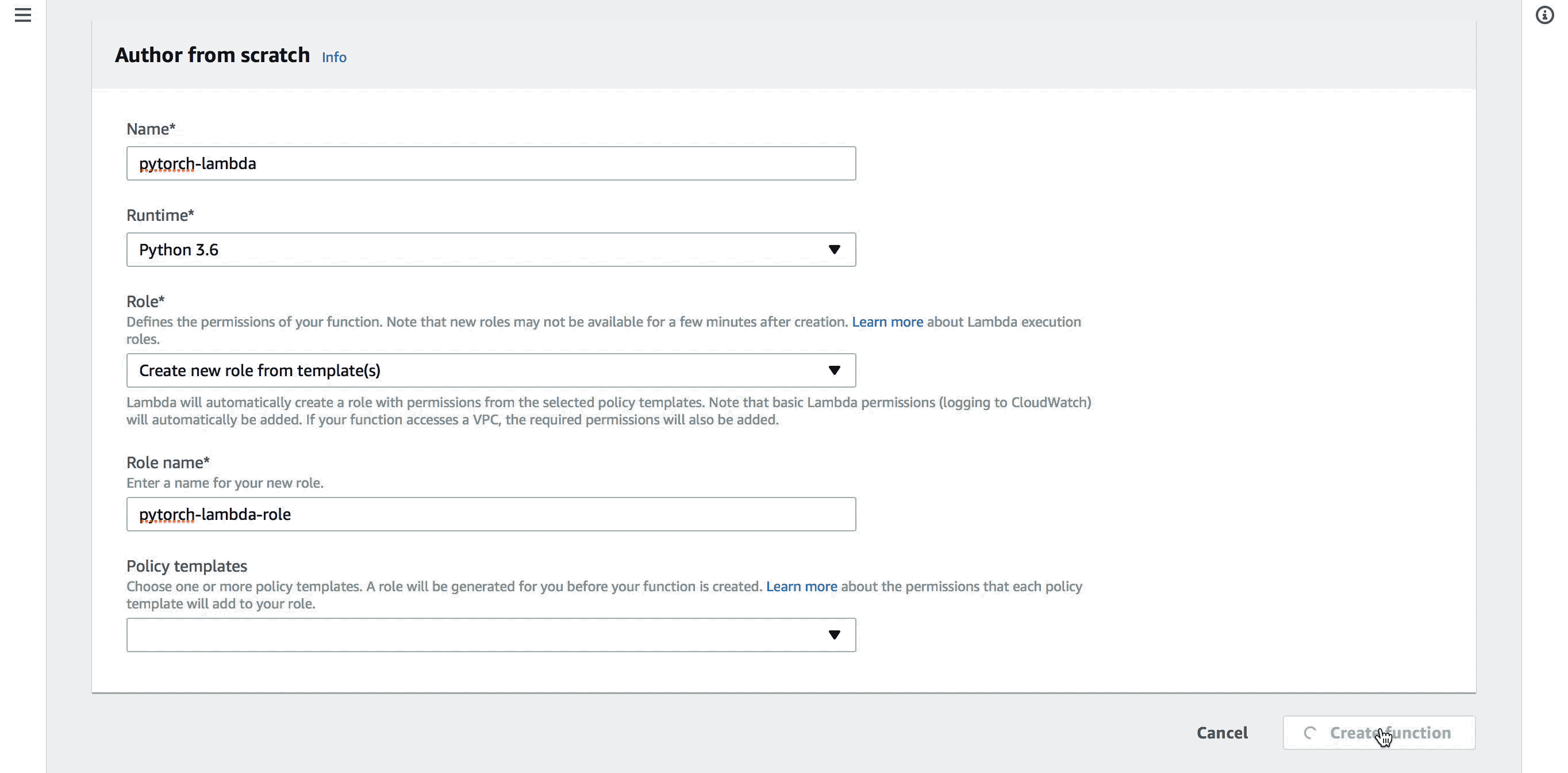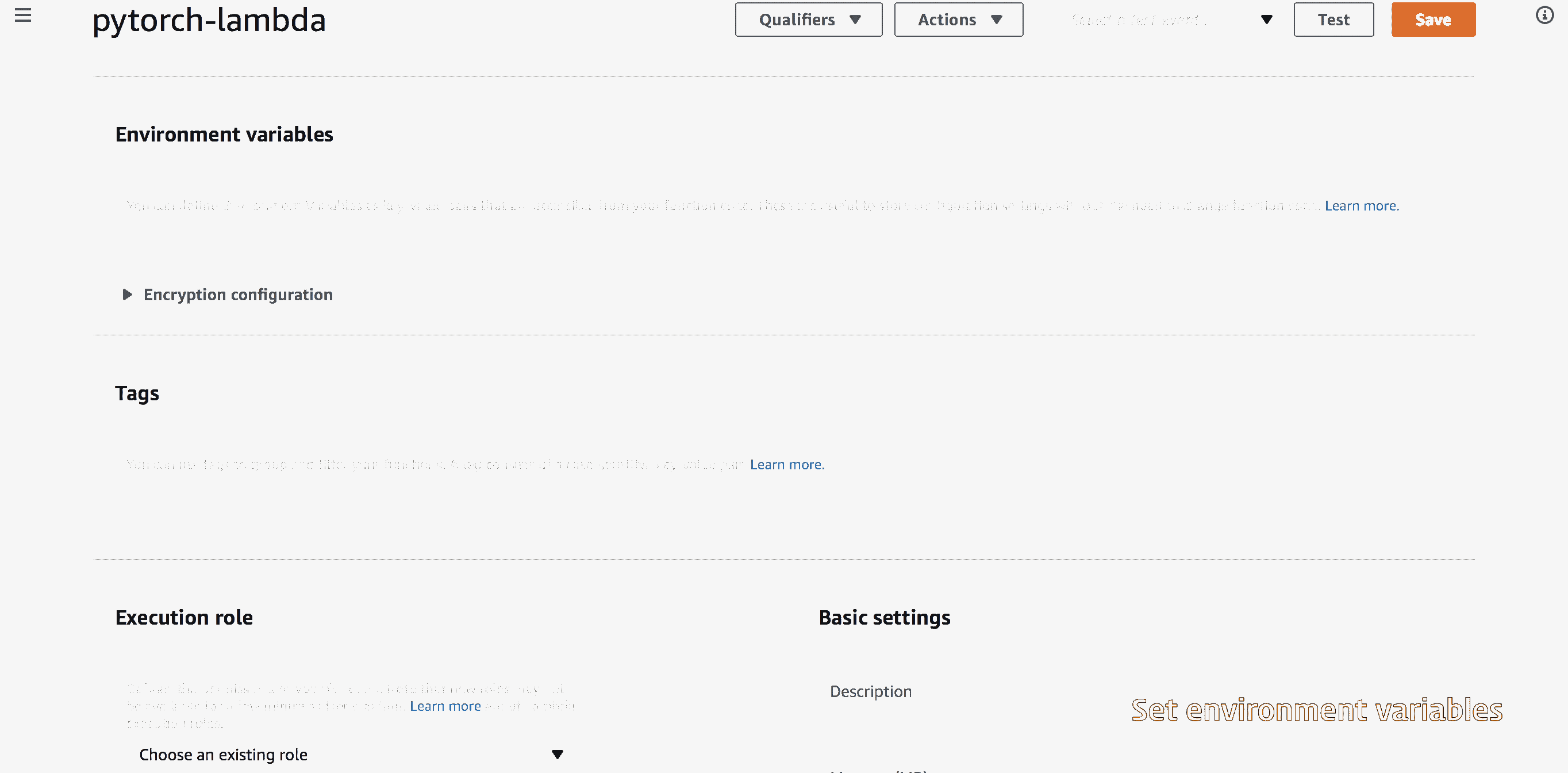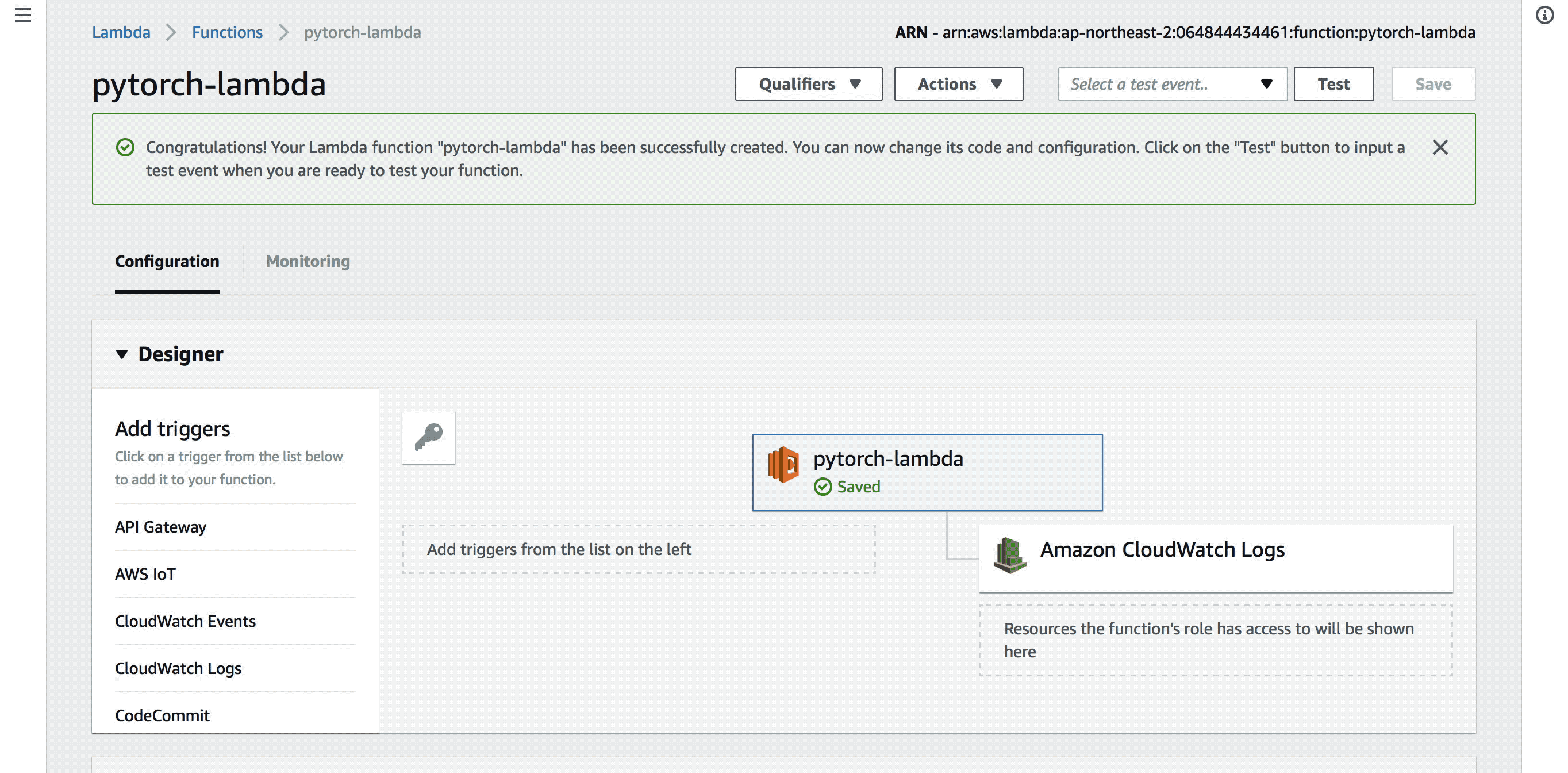
여기서는 lambda 함수의 메모리와 시간 제한을 최대인 3GB와 5분으로 정했습니다. 이 제한은 필요한 만큼 설정하시면 됩니다.
API Gateway로 API 만들기#
이렇게 설정한 lambda를 API로 만들어서 서비스할 차례입니다. API Gateway에서 새 API를 만들며 이미 있는 lambda 함수에 연결할 수 있습니다.
이 예제에서는 도메인이 다른 리소스에 접속할 수 있게 CORS 설정을 하는 부분까지 담았습니다.
AWS의 API Gateway에서는 Deployment stage를 설정할 수 있습니다. 이를 통해서 개발 버전과 서비스 버전을 분리할 수 있습니다. 버전의 이름은 보통 prob, live 또는 dev 등으로 짓습니다.
API를 설정하고 나면 마지막으로 API를 호출할 수 있는 URL을 얻게 됩니다.
테스트하기#
만들어진 API는 POST method로 호출해야 합니다. 커멘드 라인에서 url을 호출할 수 있게 해주는 curl로 간단하게 테스트 해볼 수 있습니다.
$ curl -d "{\"category\":\"Russian\", \"start_letters\":\"RUS\"}" -X POST https://tcodv2ela9.execute-api.ap-northeast-2.amazonaws.com/v1
{"statusCode": 200, "headers": {"Content-Type": "application/json"}, "body": "[\"Rovantov\", \"Uarthin\", \"Shantov\"]"}
lambda의 로그 확인은 AWS CloudWatch에서 합니다. CloudWatch > Logs > Log Group 선택 > Log Stream 선택으로 로그를 확인할 수 있습니다.
빠른 개발을 위해서#
lambda 함수를 개발하고 테스트하는 한 사이클에는 상당한 시간이 걸립니다. 코딩을 하고, docker에 환경을 구축한 뒤 압축해서 zip 파일로 만들고, 이를 S3에 업로드하고 다시 lambda에 넣은 뒤 url을 호출해 보아야 코드에 버그가 있는지 없는지 알 수 있습니다. 버그를 확인한 후 코드를 수정하고 나면 다시 위의 과정을 반복해야 하죠.
코딩을 하고 테스트로 피드백을 받는 간격이 짧으면 짧을 수록 개발 속도는 빨라지게 됩니다. 빠른 개발을 위해서 github에는 위에 설명드린 파일 외에 몇가지 파일들이 더 있습니다.
add_pack_script.sh는 build_pack_script.sh의 간소화된 버전이라고 할 수 있습니다. add_pack_script.sh는 Amazon Linux 환경을 다시 구축하는 과정을 생략하고 이미 만들어진 container 위에 파이썬 패키지 압축만 다시 합니다. lambda_function.py 등 몇가지 파일만 수정한 뒤 압축 파일을 다시 만들어야 할 때 유용하게 쓸 수 있습니다.
local_test.py와 local_test_script.sh는 로컬에서 테스트를 할 수 있게 해주는 스크립트입니다. local_test.py를 수정하여 필요한 환경 변수와 event를 지정한 뒤 사용할 수 있습니다.
마치며#
이것으로 PyTorch 모델을 AWS Lambda로 서빙하는 과정을 마쳤습니다. PyTorch와 AWS Lambda의 조합은 간단한 딥러닝 모델을 서빙하는 데 최적의 조합입니다. 요청이 없을 때는 과금이 없으며, 요청이 갑자기 많아지더라도 서버가 죽을 걱정이 없이 서비스할 수 있기 때문이죠.
이제 여러분도 딥러닝 모델을 만드는 것에서 끝나는 것이 아니라 언제 어디서나 사용할 수 있도록 서비스화할 수 있습니다.